Google Unveils Simula: A Reasoning-Centric System for Building Controllable, Scalable Synthetic Datasets Across Specialized AI Fields

Google Unveils Simula: A Reasoning-Centric System for Building Controllable, Scalable Synthetic Datasets Across Specialized AI Fields
There's a quiet crisis happening in AI right now that most people aren't talking about. It's not about model size, inference speed, or even compute costs. It's about data — specifically, the kind of specialized data that the next generation of AI systems desperately needs to get smarter.
Training a general chatbot is one thing. You can scrape the internet, throw billions of tokens at a model, and get something that knows a little bit about everything. But what happens when you need an AI that truly understands cybersecurity threat intelligence? Or one that can reason through Swiss federal law? Or one that can solve niche physics problems written in Nepali?
The internet won't save you there. That data either doesn't exist in large enough quantities, lives behind privacy walls, or is so specialized that scraping it would still leave your model with massive blind spots.
Google's research team, working alongside researchers from EPFL, just published something that takes a serious crack at this problem. It's called Simula, a reasoning-first framework for generating synthetic datasets that are actually good enough to train specialized AI models on. And the way it works is genuinely different from what's come before.
The Real Problem With AI Training Data Nobody Wants to Admit
If you've spent any time around model fine-tuning or domain-specific AI development, you've probably hit the wall. You know the one. You need more data, better data, more varied data — and there's just not enough of it.
The “obvious” solution is to ask a large language model to generate training data for you. Sounds simple enough. But anyone who's actually tried this knows it produces pretty mediocre results when done carelessly.
Here's why: most synthetic data generation methods treat data quality as the only thing that matters. But the researchers behind Simula argue there are actually three things that matter simultaneously:
Quality — Does the data point actually meet the task requirements? Is the answer correct? Is the format right?
Diversity — Does your dataset cover the full space of the domain, or does it just keep generating variations of the most common examples? Does it handle rare edge cases, or does it cluster around the obvious stuff?
Complexity — Is the data appropriately challenging? Does it push the student model to actually learn something, or is it all easy examples that any model could already get right?
The hard part is controlling all three at the same time. Most existing methods can handle one, maybe two of these axes. Controlling all three simultaneously, at scale, with transparency into how the data was constructed — that's what Simula is built to do.
What Makes Simula Different From What Already Exists
Before getting into how Simula works, it's worth understanding what it's replacing.
Most synthetic data pipelines either start from seed examples (human-curated samples that get paraphrased, mutated, or expanded) or use evolutionary algorithms (where you iteratively mutate and select data that scores well on some quality metric). Both approaches have serious drawbacks.
Seed-dependent methods are only as broad as your seeds. If your hand-collected examples happen to miss an entire subcategory of the domain, your synthetic dataset will miss it too. Evolutionary algorithms tend to converge on whatever the optimization target rewards, which often means they sacrifice diversity for quality.
Simula takes a completely different approach. It doesn't need seed data from the target domain. It doesn't use evolutionary algorithms. It reasons from first principles about what a good dataset should look like for a given domain, then constructs that dataset systematically.
The researchers describe this as treating data generation as a mechanism design problem — essentially, you're designing the rules and structures that produce good data, rather than trying to generate good data directly.
Breaking Down Simula's Four-Step Generation Process
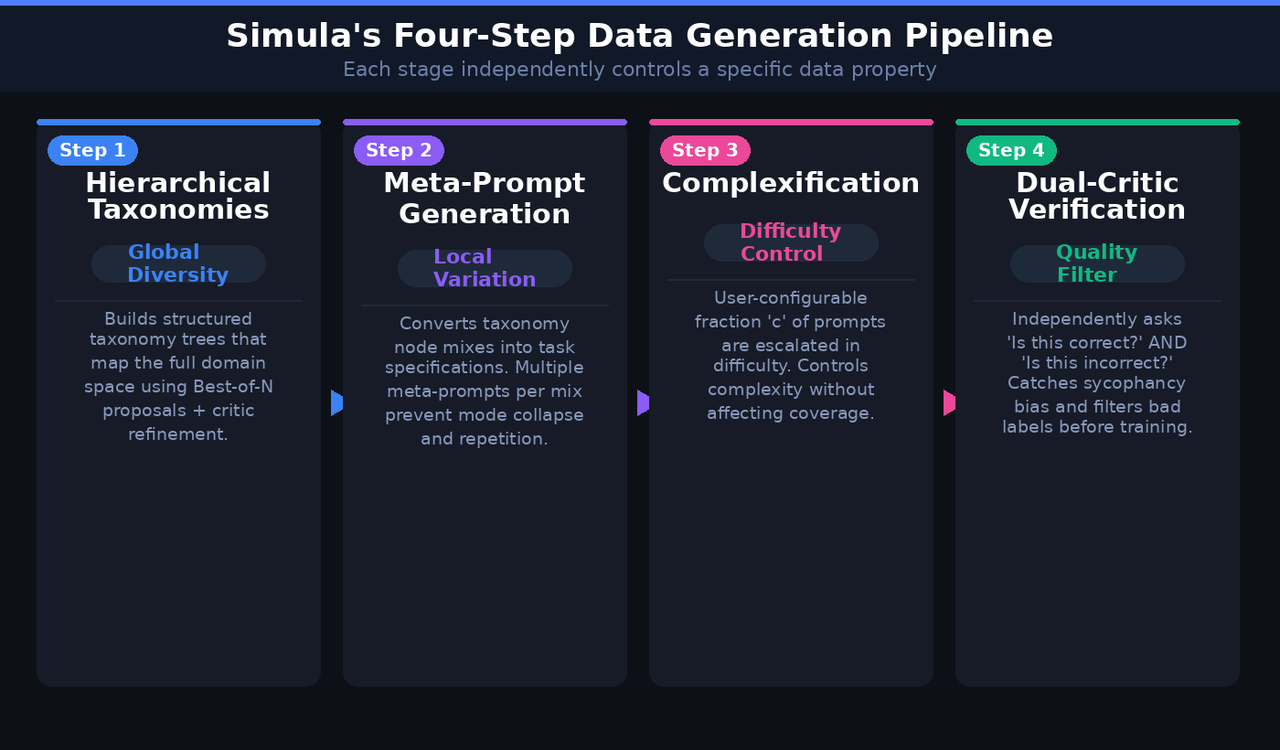
Simula breaks dataset creation into four distinct, independently controllable steps. Each one targets a specific data property, and the system uses a multimodal model (which the paper refers to as M3) to drive the reasoning at each stage.
Step 1: Building Hierarchical Taxonomies for Global Coverage
The first step solves the global diversity problem — the problem of making sure your dataset actually covers the full space of a domain, including the rare and unusual corners.
When you give Simula a dataset description, like “a dataset of cybersecurity threat intelligence questions,” the system prompts the M3 model to figure out the prime factors of variation in that domain. What are the different dimensions along which cybersecurity threat intelligence questions can vary? Attack type, threat actor, vulnerability class, mitigation strategy — those are the kinds of factors it identifies.
Each of those factors then gets expanded into a hierarchical taxonomy tree, built breadth-first. Think of it like a decision tree that maps the entire conceptual space of the domain.
To reduce the chance of missing important subcategories, Simula uses a Best-of-N proposal strategy combined with a critic refinement step. The model proposes N candidate child nodes for each tree branch, then critiques those proposals for completeness, soundness, and specificity. The goal is to catch gaps before they become gaps in your training data.
Once the taxonomy trees are built, they function as structured sampling scaffolds. When you need to generate 512,000 training examples, you sample combinations from across the taxonomy rather than letting the model generate whatever comes naturally. That's what ensures you're actually covering the long tail of the domain rather than endlessly generating variations of the most common examples.
Step 2: Meta-Prompts for Local Variation
Having a broad taxonomy is necessary but not sufficient. You also need variation within each leaf node of that taxonomy. Two examples drawn from the same category shouldn't just be copies of each other with different surface-level wording.
This is what the second step handles. Sampled combinations of taxonomy nodes are called “mixes,” and these mixes get passed to the M3 model to generate what Simula calls meta-prompts. These are task specifications rather than actual data points.
A mix of concepts like house cat, poem, and travel enthusiast might produce a meta-prompt like: “Compose an exciting haiku about a house cat who goes on an adventure.” That meta-prompt then drives actual data generation.
To prevent mode collapse — the problem where many prompts derived from the same node-set end up generating essentially the same thing — Simula generates multiple meta-prompts simultaneously from each mix and then sub-samples the required fraction. This way you get distinct instantiations rather than subtle repetitions of the same underlying idea.
Step 3: Complexification for Calibrated Difficulty
Once you have your meta-prompts, you can control how hard the generated data is going to be.
Simula includes a complexification step that operates on a user-configurable fraction of meta-prompts. That fraction, called c, determines what proportion of your dataset will get the difficulty-increase treatment.
The M3 model is prompted to increase the complexity of both the meta-prompt itself and the expected outputs, while maintaining all the other requirements of the task. This keeps complexity control completely separate from coverage control — you can turn up the difficulty dial without shrinking the breadth of your dataset.
Why does this matter? Because there's a real difference between a dataset that covers 1,000 different cybersecurity scenarios at a basic level and one that covers 1,000 different scenarios at a level that actually challenges an advanced model. The first might be fine for getting a model off the ground. The second is what you need if you want the model to perform at the upper end of the capability range.
Step 4: Dual-Critic Quality Filtering
The final step handles quality — but with a twist that's smarter than most quality filters you'll see in synthetic data pipelines.
Rather than asking the model once whether a generated answer is correct, Simula independently asks it two questions: “Is this answer correct?” and “Is this answer incorrect?” Both questions are asked separately, and the results are compared.
This dual-critic verification design addresses a well-known problem in LLM-based evaluation called sycophancy bias. LLMs have a tendency to agree with whatever sounds plausible, even if it's actually wrong. When you ask “is this correct?” and the answer is plausible, the model often says yes. But when you ask “is this incorrect?” the same model might catch errors it missed the first time.
By running both checks independently and filtering out cases where the model gives contradictory or uncertain signals, Simula significantly improves the quality of its generated labels without requiring human annotation.
The Experiments: Real Numbers on Real Domains
The research team didn't just build the system — they tested it across five genuinely challenging domains and reported results with appropriate statistical rigor (10 LoRA fine-tuning runs per configuration, 95% confidence intervals).
They used Gemini 2.5 Flash (non-thinking mode) as the teacher model and Gemma 3 4B as the student model, generating datasets of up to 512,000 data points.
The five domains tested were:
- CTI-MCQ: Multiple-choice questions for cybersecurity threat intelligence, covering CTI standards, known threats, and mitigation strategies
- CTI-RCM: An open-ended task requiring the model to map a Common Vulnerabilities and Exposures (CVE) description to the correct Common Weakness Enumeration (CWE) category
- LEXam: Law exam questions covering Swiss federal law, EU regulations, and international law, in both English and German
- GSM8k: Grade-school math word problems
- Global MMLU: Math, computer science, and physics questions in English, Korean, and Nepali
Across all five domains and all dataset sizes tested, the full Simula system consistently outperformed simpler baseline configurations. That consistency across such different domains is actually a pretty significant result — it's easy to build a system that works well on one domain type and falls apart on others.
What the Complexity Experiments Actually Revealed
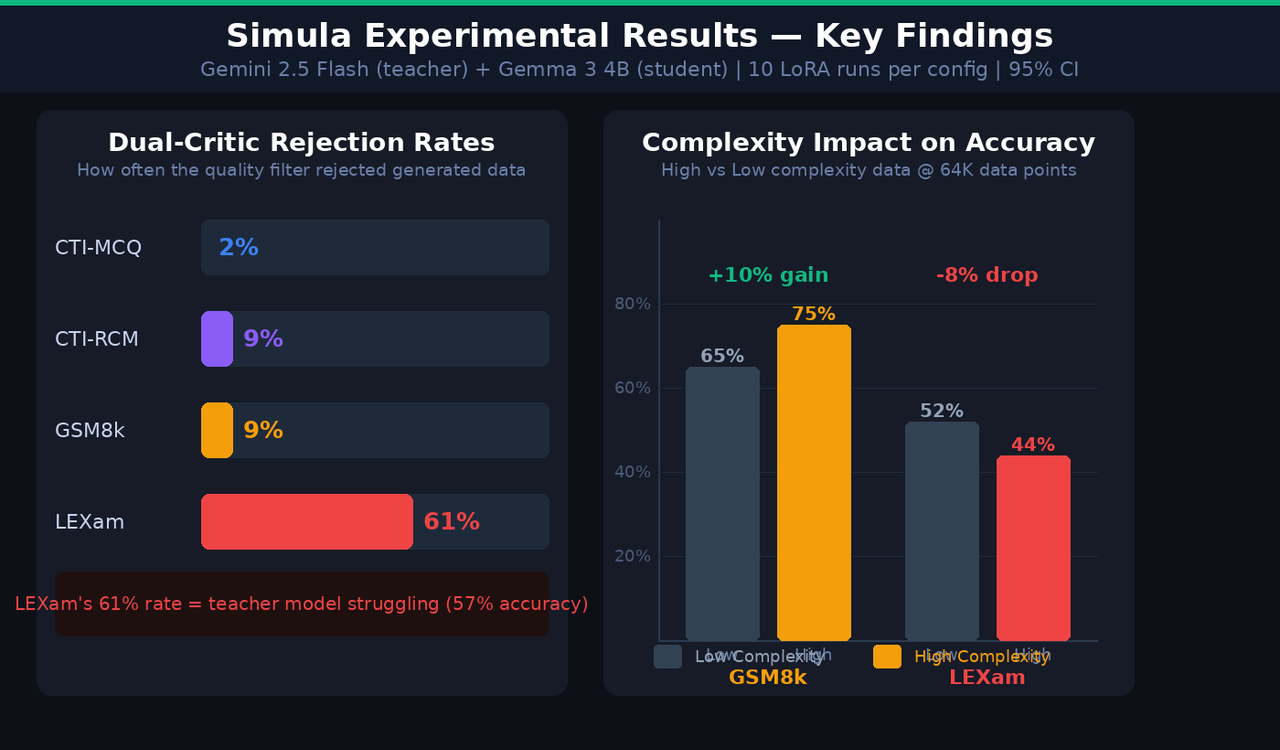
The complexity results were some of the most practically useful findings in the paper.
On GSM8k, using the High Complexity data split produced a 10% accuracy gain over the Low Complexity split at 64,000 data items. If you're trying to train a model to solve harder math problems, harder training data makes it better at harder math problems. That tracks.
But on LEXam, the story was completely different. Higher complexity data actually hurt model performance.
Why? Because the teacher model — Gemini 2.5 Flash — only achieved 57% accuracy on LEXam questions. The domain is genuinely hard, and the teacher wasn't reliable enough to generate correct labels for the most complex examples. So the high-complexity data was contaminating the training set with wrong answers, and the student model learned the wrong things.
This shows up clearly in the critic rejection rates. For LEXam, the dual-critic system rejected 61% of generated data points. For CTI-MCQ it was just 2%. For GSM8k, 9%. The rejection rate is essentially a signal of how reliable your teacher model is on the domain — and if your teacher can't reliably label complex examples, generating complex examples is counterproductive.
The takeaway is practical: complexity is a tool, not a default setting. You should dial it up when your teacher model is strong, and dial it down (or leave it off) when your teacher model is struggling.
The Student-Teacher Gap and Why Scaling Laws Are More Complicated Than They Look
One of the more interesting findings involves what the researchers call the Student-Teacher Gap effect on data scaling laws.
For CTI-RCM, the student model's performance stopped improving at around 128,000 data points. At that point, it had bridged about 83% of the gap between its starting accuracy (40%) and the teacher model's performance ceiling (70%). Adding more data beyond that point produced diminishing returns because the student was essentially bumping up against the ceiling that the teacher's reliability imposed.
GSM8k behaved completely differently. There was no such saturation because the student's peak performance (75%) was still meaningfully below the teacher's level (88%). With more headroom to grow, more data kept helping.
This has real implications for how you should think about synthetic data budgets. The question isn't just “how much data do I need?” It's “how close to the teacher ceiling am I, and is that ceiling high enough?” If the gap between student and teacher is large and the teacher is accurate, keep generating more data. If the student is already close to the teacher's ceiling, you might be wasting compute generating more of the same.
Rethinking How We Measure Dataset Quality
Beyond the generation framework itself, the Simula paper introduces two new approaches to evaluating synthetic datasets intrinsically — meaning you can assess quality without needing a downstream benchmark.
Taxonomic Coverage Scoring
Most existing diversity metrics for datasets rely on embedding-based cosine distance. You embed all your data points, compute pairwise distances, and use that as a proxy for how diverse the dataset is. The problem is that cosine distance doesn't tell you what you're missing. It just tells you that your points are, on average, X distance apart in embedding space.
Taxonomic Coverage does something much more actionable. It measures what fraction of taxonomy nodes at each level of the hierarchy are represented in your dataset. If you have a 10-node taxonomy at the third level and your dataset only hits 6 of those nodes, you immediately know there are 4 subcategories you're underrepresented in — and you can target them specifically.
What the researchers found when applying this metric was striking: real-world reference datasets almost always cover less of the target domain than Simula-generated versions, even when the embedding-based cosine distance metrics say the real-world datasets are more diverse. This is a meaningful critique of how the field has been measuring dataset quality — the standard metric is telling a misleading story.
Calibrated Complexity Scoring
The second evaluation method assigns Elo ratings to individual data points by running batch-wise pairwise comparisons. The system asks the M3 model to compare pairs of examples and judge which is more complex, accumulating these comparisons into a calibrated complexity score for each data point.
The researchers validated this approach against human-annotated complexity labels on the MATH dataset and found strong alignment. The method is called “calibrated attribute scoring” and it works for any attribute you want to measure, not just complexity — you could in principle apply the same approach to measure difficulty, specificity, or any other axis you care about.
Why This Actually Matters for the Future of AI Development
Let's step back from the technical details for a second and think about what Simula represents at a higher level.
The reason this matters is that the next serious frontier for AI improvement isn't going to come from just scaling up general training data. It's going to come from getting AI systems to be genuinely competent in domains that require real expertise: healthcare, law, security, scientific research, engineering.
Those domains share a common challenge: the relevant knowledge is specialized, often private, expensive to annotate, and not well-represented in general internet data. You can't just scrape your way to a good medical AI or a good legal AI.
Simula's approach — generating structured, coverage-aware, complexity-controlled training data from first principles — is a serious attempt to build a path around this bottleneck. The fact that it works across domains as different as cybersecurity threat intelligence, Swiss law, and grade-school math suggests it might actually generalize.
The transparency angle also matters. Because the dataset is built on explicit taxonomy trees, you can inspect exactly what the generator was trying to cover, audit which nodes are underrepresented, and deliberately fill gaps. That kind of auditability doesn't exist in most synthetic data pipelines today.
The Pieces That Still Need Work
Being honest about limitations: the system requires more inference calls than simpler approaches. The paper notes that the full Simula pipeline uses up to 5x more inference calls per data point compared to baseline methods. That's a real cost, though the researchers argue it's justified because you reach higher downstream performance with fewer total data points — so the per-data-point cost increase is offset by needing a smaller dataset to hit a given performance target.
The teacher model quality bottleneck is also real. As LEXam demonstrated, when your teacher model isn't reliable on a domain, Simula's quality filters will catch a lot of bad data — but they can't rescue bad data that looks plausible. If the teacher confidently generates incorrect labels that the dual-critic system doesn't catch, that noise ends up in your training set.
And the taxonomy construction step, while systematic, still relies on the M3 model's understanding of a domain. For extremely niche or unusual domains that are poorly represented in that model's training, the taxonomy might miss important subcategories even with the Best-of-N critic refinement in place.
What Researchers and Practitioners Can Take Away
If you're working on domain-specific AI development, there are several things worth pulling from this work:
Think about data as a three-dimensional object. Quality, diversity, and complexity are all independent axes. A dataset that scores high on one doesn't automatically score high on the others. Build your pipelines to control each one deliberately.
Check your teacher model's ceiling before scaling up. If your teacher model struggles with the domain, high-complexity data will likely hurt you. The dual-critic rejection rate is a useful diagnostic signal here — if it's over 50%, your teacher is struggling.
Don't trust cosine distance as your only diversity metric. It can tell you how spread out your embeddings are, but it can't tell you which parts of the domain you're systematically missing. Coverage-based metrics grounded in an explicit taxonomy give you much more actionable information.
Scaling data isn't always the answer. If your student model has already closed most of the gap to the teacher, adding more data yields diminishing returns. Know where you are on the scaling curve before committing more compute to data generation.
Closing Thoughts
Google's Simula framework doesn't solve every problem in synthetic data generation. No single paper does. But it's one of the more thoughtfully constructed approaches to a problem that's going to become more pressing as the field pushes into specialized domains.
The core idea — that good synthetic data requires simultaneous, independent control over quality, diversity, and complexity, and that you can achieve this through structured reasoning from first principles rather than through seed data or evolutionary search — is genuinely worth paying attention to.
The evaluation contributions (taxonomic coverage scoring and calibrated complexity scoring) might end up being just as influential as the generation framework itself, because the field has been flying somewhat blind on dataset quality for a while.
If you want to go deeper, the full paper and the Google Research blog post are linked below. The blog post is a more accessible read; the paper has all the experimental details.
Read the full paper: Simula: A Reasoning-First Framework for Synthetic Data Generation
Read the Google Research blog: Designing Synthetic Datasets for the Real World: Mechanism Design and Reasoning from First Principles
More Posts:
- OpenAI Launches $100 ChatGPT Pro Plan with 5x Higher Codex Limits Than Plus
- What Is Search Box Optimization (SBO) and Why It’s the Next Big Thing in Digital Marketing
- How One AI Platform Is Replacing 10 Separate Tools (And Why Creators Are Taking Notice)
- Anthropic Unveils Claude Opus 4.7
- OpenAI Unveils GPT-Rosalind, a Restricted-Access Life Sciences Model Alongside an Expanded Codex GitHub Plugin