NVIDIA Polar explained: training AI coding agents with token-faithful GRPO
NVIDIA Polar explained: training AI coding agents with token-faithful GRPO
Reinforcement learning for language models hit a wall nobody talks about enough. Not the data wall, not the compute wall. The integration wall. You have a sophisticated agent harness — something that took months to build, tuned for specific tool schemas, context policies, multi-agent orchestration — and you want to run RL on top of it. Standard frameworks tell you to rewrite everything behind their interfaces. Most teams give up or ship a half-baked version that loses critical training signals along the way.
NVIDIA's answer is Polar. And it takes a completely different angle.
The problem with how RL training has worked
Every major RL training framework — think OpenAI Gym, SkyRL, PRIME-RL — assumes you can wrap your training target inside a clean, standard interface. env.step(), env.reset(), neat little reward signals after each action. That worked fine when the training target was a game or a toy task.
Agentic settings break this assumption entirely.
Real software-engineering agents — tools like Claude Code, Codex, Qwen Code — are not Python classes you can cleanly subclass. They manage long-running context, spawn sub-agents, apply context compaction strategies, issue dozens of tool calls across tens of thousands of tokens. Solving a single GitHub issue can generate hundreds of model completions. These systems have their own internal event loops, formatting conventions, error recovery behaviors. They evolved that way for good reasons.
So when a team at NVIDIA wanted to run RL over these harnesses without destroying what makes them good, they asked a question that sounds obvious in retrospect: what does every LLM-based agent have in common, regardless of how it's built internally?
It talks to a model.
What Polar actually does
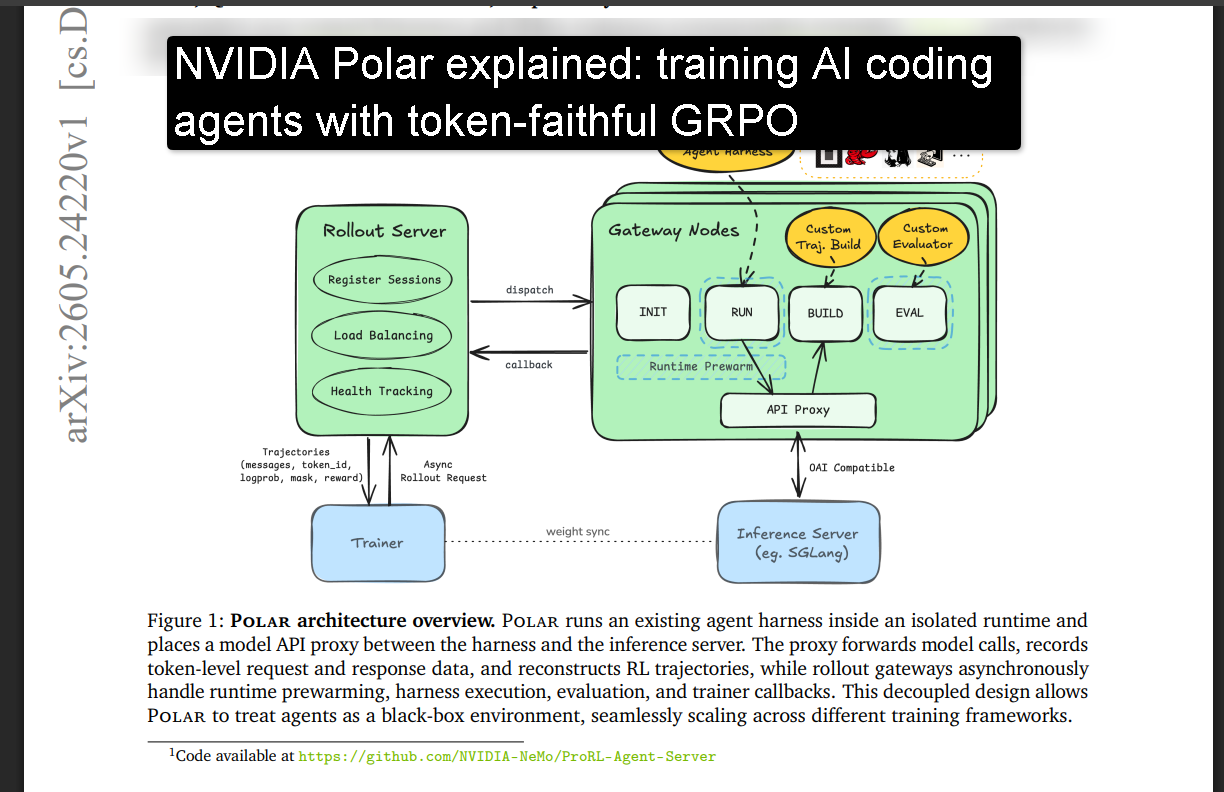
Polar sits at the model API boundary rather than the harness boundary. Instead of requiring the harness to implement some framework-specific interface, Polar places a proxy between the harness and the inference server. The harness thinks it's talking to OpenAI or Anthropic. It's actually talking to Polar's gateway, which records everything at the token level and hands it to the trainer.
This is a genuinely different integration philosophy. The harness runs unchanged. Not “mostly unchanged with a few shims.” Completely unchanged. A harness adapter in Polar is tiny — it might set some environment variables, configure which model endpoint to use, and return the shell command that launches the agent. That's it.
The proxy itself supports Anthropic Messages, OpenAI Chat Completions, OpenAI Responses, and Google generateContent-style calls. It normalizes them to whatever format the local inference server expects, adds the fields needed for training like logprobs=true, captures token-level data, and returns responses in whatever format the harness expects. For harnesses that need streaming responses, Polar gets a non-streaming upstream response and synthesizes a provider-shaped stream. The harness never notices.
Token fidelity: why it matters more than you think
There's a subtle but catastrophic failure mode in agentic RL training called retokenization drift. When a harness logs a conversation as text and you try to reconstruct token IDs from that text later, re-encoding can produce different tokens than the originals. Your training signal attaches to the wrong tokens. Your gradient updates are wrong. Your model learns the wrong behavior.
The vLLM team's Agent Lightning work made this problem visible. Polar takes it seriously at the architecture level.
Because Polar sits at the API boundary and records the raw token IDs and log probabilities directly from inference backend responses, it never has to re-encode anything. The tokens that went into generating the response are the tokens that get marked as trainable. Non-generated interstitial tokens — the context the harness inserted between turns, canonical message formatting, tool call structures — get masked out. Only behavior-policy tokens are trained on.
This invariant is the backbone of Polar's correctness guarantee: every trainable token in every emitted trace matches what the model actually sampled during rollout.
Inside the architecture
Polar has two major components: a rollout server and gateway nodes. They do different things.
The rollout server takes task requests, expands them into independent sessions (you might want 16 rollout samples per prompt for GRPO), dispatches sessions to gateway nodes, tracks session health, and accepts callbacks when sessions complete. It's the global scheduler.
Gateway nodes own individual sessions. Each gateway starts the runtime (Docker or Apptainer for HPC environments), runs the harness, hosts the model proxy, builds trajectories, runs the evaluator, tears everything down, and calls back the rollout server. The proxy and the session registry live on the same node deliberately — this avoids a separate trace-collection service and keeps captured completions directly tied to the right session.
Training frameworks connect to Polar as external clients. A background worker submits tasks, receives completion callbacks, converts traces into whatever format the trainer expects, and the trainer runs independently. This decoupling means rollout can scale completely separately from GPU training, which matters enormously for long-horizon agent tasks where rollout time dominates.
The async staging problem
Long-horizon agent rollouts have wildly different cost profiles at different stages. Setting up a Docker container with the right commit checked out, dependencies installed, and the harness ready: CPU-bound and slow. Running the agent: GPU-bound and variable-length. Running SWE-Bench evaluation on the patch: CPU-bound again, can take minutes.
If you handle all this sequentially, your expensive GPUs sit idle while containers spin up and tests run.
Polar solves this with isolated worker pools inside each gateway. INIT workers prepare runtimes in the background. A bounded READY buffer holds initialized runtimes waiting for an execution slot. RUNNING workers execute harnesses. POSTRUN workers build trajectories, run evaluators, send callbacks, and tear down resources. These pools operate independently, so runtime preparation and evaluation don't block active agent execution.
The evaluator prewarm feature takes this further: when an evaluator needs a clean runtime for post-run testing, the gateway starts preparing that runtime during the agent run rather than after it finishes. Dead time collapses.
Trajectory reconstruction strategies
Once the proxy has captured a sequence of model completions for a session, Polar needs to convert them into trainer-facing traces. Two strategies are available, and the choice has major performance implications.
The conservative approach, called per_request, treats each completion as an independent trace. It's lossless in the sense that every model call produces a training sample. The problem: a complex coding session can generate hundreds of completions. Your trainer receives hundreds of micro-updates per task. For GRPO specifically, where credit assignment works at the session level, broadcasting a session-level reward to hundreds of request-level traces creates serious reward hacking problems — traces that contributed nothing to solving the task receive the same reward as traces that did the critical work.
The prefix_merging strategy reconstructs longer traces from completion sequences where the conversation history grows monotonically. It doesn't assume the whole session is one linear conversation — it partitions completions into chains, where a completion can join a chain only if its prompt token sequence contains the previous prompt as a strict prefix. Sub-agents, context compaction events, and parallel branches naturally form separate chains rather than being forced into one global trace.
Within each chain, merging works carefully. The sampled response tokens from each completion — the actual behavior-policy tokens — are copied directly. The interstitial tokens inserted by the harness between turns are taken from the canonical prompt tokenization and masked out in the loss mask. The loss mask is what enforces the correctness invariant: 1 on trainable tokens, 0 on everything else.
The performance difference between these strategies is striking. In Polar's own experiments, prefix_merging reduced a stream of 1,185 request-level updates to 218 merged-trace updates over three training steps. Wall-clock time dropped from 189.5 minutes to 35.2 minutes — a 5.39x speedup. Rollout GPU utilization held at 87.7% average versus 20.4% for per_request over the same window. The math here is simple: fewer, longer traces mean fewer trainer updates, which means GPUs spend more time inferencing and less time waiting.
What the experiments showed
The NVIDIA team validated Polar by running GRPO on SWE-Bench Verified — real GitHub issues from open-source repositories — using four different coding harnesses: Codex, Claude Code, Qwen Code, and Pi. All experiments started from the same Qwen3.5-4B base checkpoint. Training data came from the SkyRL-v0-293-data SWE-Gym dataset.
The results across harnesses break down clearly:
Codex: Base model sits at 3.8% pass@1. After Polar RL training, it reaches 26.4%. A 22.6 point absolute gain. The explanation is that Codex uses an unfamiliar action protocol, context policy, and patch submission style relative to the base Qwen model's training distribution. Polar keeps that exact execution path intact during training — reward attaches to the actual tokens flowing through Codex — so GRPO optimizes the behavior the model must produce at evaluation time. No mismatch between training and deployment.
Claude Code: Base model at 29.8%, reaches 34.6% after training. A 4.8 point gain. Training curves show the per-step reward rising from 28.8% average over the first ten steps to 67.0% over the last ten, showing that learning is happening throughout training even when the final benchmark gain looks modest.
Qwen Code: Base model at 34.6%, reaches 35.2%. A smaller 0.6 point gain, which is expected — the base Qwen model is already well-aligned with its native harness, so there's less adaptation gap to close.
Pi: Base model at 34.2%, reaches 40.4%. A 6.2 point gain, with training curves showing clear consistent improvement from 61.6% to 76.2% reward over first and last ten steps.
These results confirm the core claim: harness-native RL delivers large adaptation gains when the model encounters an unfamiliar execution environment, and still finds gains in familiar environments. The framework itself is not the bottleneck.
Offline data generation as a bonus
RL training is the headline use case, but Polar does something else worth noting: offline SFT data generation at scale.
The NVIDIA team ran a case study using Qwen3.5-122B-A10B with the Pi harness against 1,638 SWE-Gym instances drawn from repositories including getmoto/moto, python/mypy, pydantic/pydantic, and pandas-dev/pandas. The setup ran on a single 8×H100 node with SGLang serving. Each task ran in its own Apptainer container built from the SWE-Gym reference image.
A trajectory was accepted into the SFT corpus only if the SWE-Bench evaluation harness confirmed that the agent's patch resolved every FAIL_TO_PASS test while leaving PASS_TO_PASS tests green. Single-bit filter, no partial credit.
Result: 504 accepted trajectories from 1,638 attempts. 30.8% overall acceptance. Roughly 64 GPU-hours. The acceptance rate varied considerably by repository — getmoto/moto accepted over 53% of attempts while dask/dask accepted under 18%, correlating with task difficulty and test suite complexity.
The accepted trajectories are available as a HuggingFace dataset under Apache-2.0 license. Each row contains SWE-Gym instance metadata and the full multi-turn conversation in OpenAI message format. Average session length: 104 messages, 51 assistant turns, with a long tail above 200 turns.
The infrastructure that generated this corpus is the same infrastructure used for online RL. You want rejection sampling? Run multiple completions per prompt and keep the ones that pass the verifier. Preference data? Pair accepted and rejected traces from the same prompt. Scale to more instances? Add submitter shards. The orchestration code stays the same.
Compared to other approaches
The comparison that matters most is against systems that already tried to solve adjacent problems.
SkyRL-Agent built a capable multi-turn agent RL stack with a Gymnasium-style interface. Its strength is efficient training once agents are expressed in its abstractions. Polar targets the earlier problem: running a pre-existing harness whose internal event loop and tool formatting should stay unchanged.
PRIME-RL handles large-scale async RL with trainer-inference separation. Polar is not a replacement trainer — it's a rollout substrate that feeds asynchronous trainers with trajectories from harnesses heavier than typical verifiable-reward functions.
Agent Lightning and rLLM both recognized that researchers shouldn't rewrite entire applications to train them. Both lower integration cost. But both still require agents to conform to prescribed interfaces — SDK callbacks, decorators, workflow abstractions. Polar's integration point is narrower: the provider API endpoint the harness already uses. This is more robust for harnesses distributed as command-line tools or binaries where internal observability isn't available.
Polar is the only system in this landscape that achieves all four properties simultaneously: async RL support, async rollout staging, rollout as a service, and genuine harness agnosticism.
The token fidelity problem in practice
It's worth spending a moment on what token fidelity actually costs when it's missing, because it's not obvious.
Agentic rollouts produce long, complex sequences. A single session might involve three turns of main agent reasoning, one context compaction event where the harness rewrites the conversation to fit in the context window, and a sub-agent spawned to handle a subtask. If you try to reconstruct the full token sequence from the text-level logs after the fact, you're almost certainly going to get different tokens at some positions. This isn't a bug in your code — it's how tokenization works. Same string, different position in sequence, different BPE merge decisions.
The consequence in RL training: your policy gradient points in a slightly wrong direction. The magnitude of “slightly wrong” scales with session complexity and trajectory length. For short single-turn tasks, this is noise. For long agentic sessions with hundreds of completions, it corrupts training.
Polar avoids this entirely by capturing the actual token IDs and log probabilities at the inference backend response level, before any re-encoding has a chance to occur. The token fidelity principle is explicit in the design: generated assistant tokens come from inference responses, interstitial tokens come from canonical prompt tokenization, and the loss mask enforces that only behavior-policy tokens are trainable.
Why the proxy boundary is the right abstraction
The deeper insight in Polar's design is that the model API boundary is a natural seam that exists independent of any RL framework. Every LLM-based agent crosses it. It's defined by open standards (OpenAI, Anthropic, Google APIs). It carries exactly the information you need for training: prompts, sampled tokens, log probabilities.
By placing the integration point here instead of inside the harness, you get a guarantee that holds for any harness: closed-source binaries, package-managed tools, shell scripts, distributed multi-process systems. If it calls an LLM, Polar can train it.
This is the kind of architectural insight that seems obvious after the fact. Before it, the field was stuck in a pattern of rebuilding every interesting agent harness from scratch in RL-framework terms. After it, you can take SWE-bench-grade coding agents — the ones that actually work well because of years of engineering — and make them trainable targets without touching their internals.
What Polar is registered as
Polar supersedes its predecessor, ProRL Agent, and is registered as one of the environments in NVIDIA's NeMo Gym — an open-source library for scaling RL environments for large language models. The codebase is open at GitHub.
The service API is small and clean: submit tasks, poll status, receive callbacks. Gateway nodes register with the rollout server and maintain heartbeats. The proxy endpoint catches all provider-style model requests and routes them through Polar's capture and normalization pipeline. Everything else — the trainer, the inference server, the harness itself — stays external.
Where this points
The open problem Polar's authors are honest about: process reward models and credit assignment for per-request traces. The per_request strategy with session-level reward broadcasting produced observable reward hacking in experiments — request-level traces getting credit for outcomes they didn't cause. prefix_merging sidesteps this by producing longer, more coherent traces, but session normalization and per-trace reward assignment for complex multi-agent sessions remain open research questions the team explicitly flags as roadmap items.
What Polar has closed is the infrastructure gap. You can now take the coding agent harnesses that actually perform well on real benchmarks, leave them architecturally intact, and run principled RL training over them at scale. The 22.6 point gain on Codex is not a benchmark number that comes from a toy setting — it's a 4B parameter model learning to operate a real agent harness the way that harness is actually used, optimized against real GitHub issue resolution with verifiable outcomes.
That's the starting point Polar hands to researchers and practitioners who want to go further.
More Posts:
- What is Vigolium? A complete guide to the open source vulnerability scanner
- How developers supercharge Codex, Claude, Antigravity, and Cursor AI with MCP servers
- Still Using a Cash Register in Your Shop Instead Of A POS System? Here Is What You Are Missing Out On
- This open-source AI video model creates 4-minute videos directly on your PC
- Claude’s New Infinite Context Window Could Change How You Work Forever