Anthropic Unveils Claude Opus 4.7

Anthropic Unveils Claude Opus 4.7
Anthropic just dropped something that has the AI world paying attention. Claude Opus 4.7 is now live and available to everyone, and if you work with code, handle complex documents, or build anything that depends on AI agents running long tasks, this release is worth understanding in detail.
This is not just a minor patch. Opus 4.7 is a real generational step up from its predecessor, Opus 4.6, with improvements that go beyond raw benchmark numbers. Think sharper vision, smarter instruction following, better memory, and a level of coding reliability that early testers are calling “game-level” different.
Let's break it all down.
What Even Is Claude Opus 4.7?
Before getting into the details, it helps to understand what Claude Opus is in the first place.
Anthropic builds AI models under the Claude brand. The Opus line represents their most powerful models, built for complex, demanding tasks. Think of it like the difference between a basic calculator app and a full-featured spreadsheet tool. Sonnet models handle everyday work well. Opus is for the hard stuff.
Claude Opus 4.7 is the newest version of that flagship line. It was released on April 16, 2026, and is now available across all Claude products, the API, Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry. Pricing stays the same as Opus 4.6: $5 per million input tokens and $25 per million output tokens.
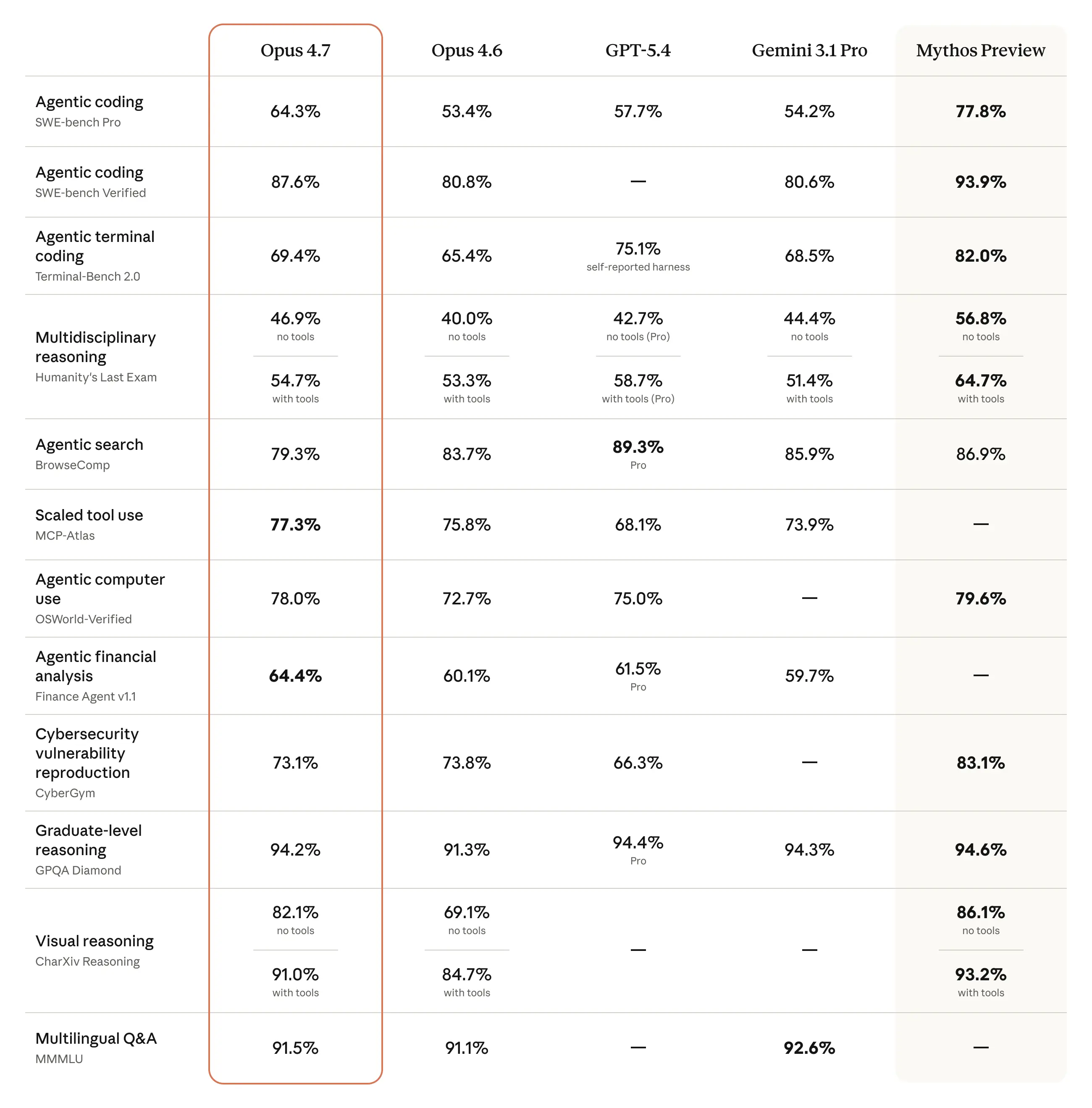
The Big Improvements: What Actually Changed
Coding Just Got Significantly Better
The most talked-about upgrade in Opus 4.7 is what it does with code. Early testers have been handing off their most difficult engineering work to this model, the kind of work that used to need constant human supervision, and getting solid results back.
One benchmark from Rakuten showed Opus 4.7 resolving three times more production tasks than Opus 4.6. CodeRabbit reported a 10 percent improvement in recall, meaning the model is catching more bugs while keeping precision stable. Cursor's internal benchmark saw the model clear 70 percent of tasks compared to 58 percent for Opus 4.6.
What makes this useful in practice is not just raw accuracy. It is how the model handles failure. Instead of stopping mid-task or generating plausible-sounding but incorrect fallbacks, Opus 4.7 pushes through problems, recovers from tool errors gracefully, and verifies its own outputs before reporting back. One team at Hex described it this way: the model correctly reports when data is missing rather than inventing something that looks right.
That kind of honesty matters a lot when you are using AI in production.
Vision That Can Actually See the Details
Previous Claude models had a resolution ceiling that made fine visual work tricky. Opus 4.7 breaks through that ceiling in a meaningful way.
The model can now process images up to 2,576 pixels on the long edge, which works out to roughly 3.75 megapixels. That is more than three times the resolution support of earlier models. For anyone building tools that need AI to read dense screenshots, analyze complex diagrams, or work with pixel-level precision, this change opens up a whole category of use cases that were not practical before.
One company called XBOW, which builds autonomous penetration testing tools, reported that their visual acuity benchmark score jumped from 54.5 percent with Opus 4.6 to 98.5 percent with Opus 4.7. They noted that their biggest pain point with the previous model effectively disappeared.
Another team, Solve Intelligence, builds tools for life sciences patent workflows. They said the higher resolution support is helping them build better tools for everything from patent drafting to infringement detection, particularly because the model can now read chemical structures and complex technical diagrams accurately.
Following Instructions the Way You Actually Wrote Them
This one is subtle but important.
Opus 4.7 is substantially better at following instructions literally. That sounds straightforward, but it has a real-world implication that Anthropic explicitly flags: prompts written for older models might now produce different results. Where previous models would interpret instructions loosely or skip parts they did not understand, Opus 4.7 takes what you write seriously and acts on it.
If you are migrating from Opus 4.6, Anthropic recommends reviewing your prompts and re-tuning them for the new model. This is not a bug. It is actually progress. But it does mean a short adjustment period if your workflows were built around the old model's habits.
Memory That Works Across Sessions
One of the most practically useful upgrades is how Opus 4.7 handles memory. The model is better at using file system-based memory, which means it can remember important notes and context from earlier parts of a long multi-session project and use them when picking up new tasks.
The result is that later tasks in a long workflow need less upfront context. You do not have to re-explain everything from scratch each time. The model builds on what it already knows.
For teams running complex, multi-day projects with AI agents, this is a genuinely meaningful quality-of-life improvement.
Real People, Real Results: What Early Testers Are Saying
Numbers on benchmarks are useful, but what matters more is whether the model actually helps people get work done. Here is what teams said after testing Opus 4.7 in real conditions.
Financial Technology
One fintech platform that serves millions of consumers said they are seeing the potential for a significant leap in developer productivity. They noted that the model catches its own logical faults during planning, which speeds up execution. For a platform where trust and precision matter, that combination of speed and accuracy is exactly what they need.
Agentic Workflows
Devin, a platform built around autonomous software engineering, said Opus 4.7 takes long-horizon autonomy to a new level. The model can work coherently for hours, pushes through hard problems rather than giving up early, and unlocks a class of investigation work that was not reliably possible before.
Notion reported that Opus 4.7 passed their implicit-need tests, the first model to do so, and continues executing even when tools fail. They called the reliability jump the thing that makes their agent feel like a real teammate.
Legal Work
Harvey, which builds AI tools for legal professionals, tested Opus 4.7 on BigLaw Bench. The model scored 90.9 percent accuracy on substantive legal questions at high effort, and showed noticeably smarter handling of ambiguous document editing tasks. Reviewers noted the model correctly distinguished between different types of contract provisions, a task that has historically tripped up even frontier models.
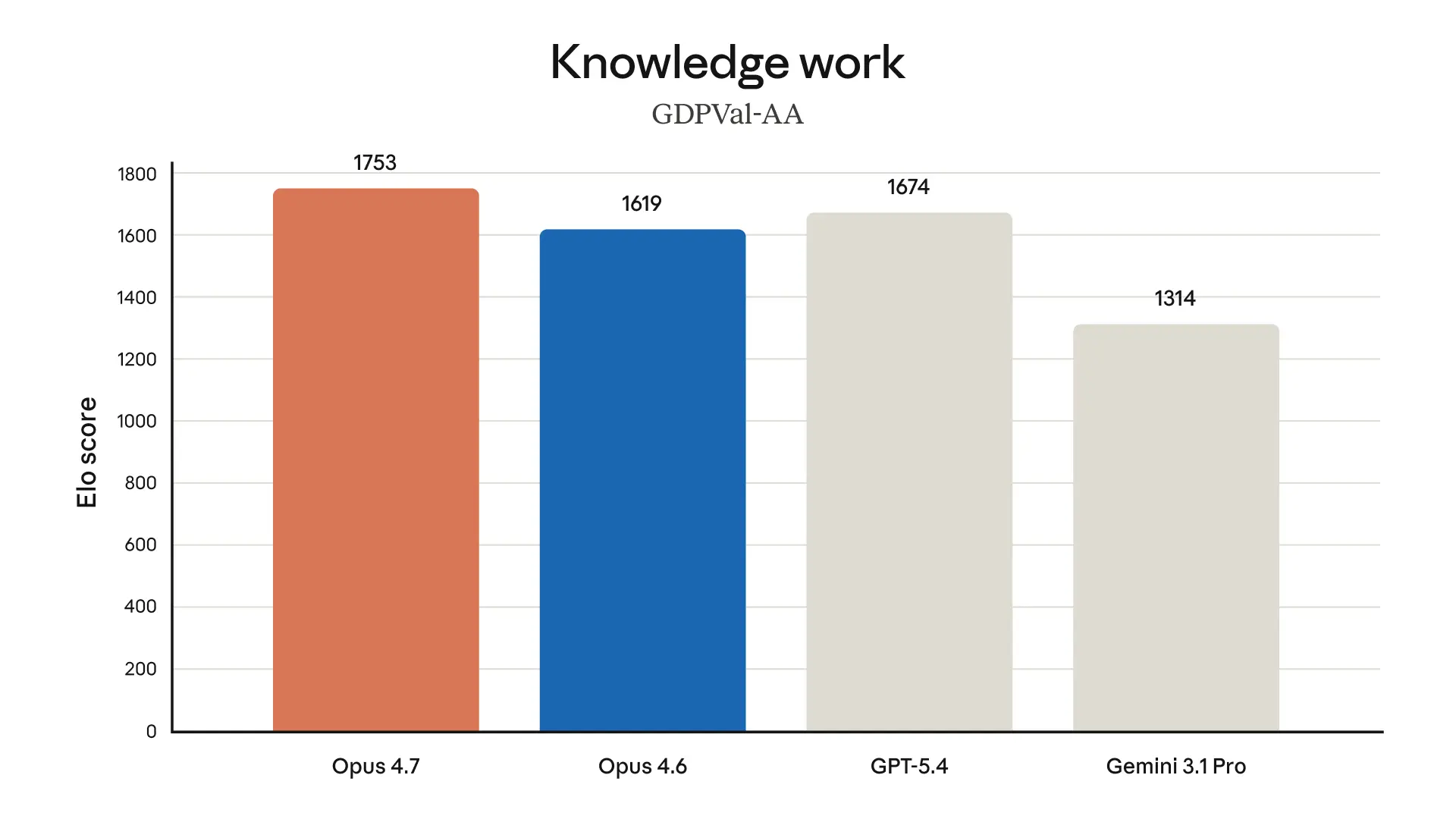
Document and Data Work
Databricks tested the model on their OfficeQA Pro benchmark and found 21 percent fewer errors than Opus 4.6 when working with source documents. Across their agentic reasoning benchmarks, Opus 4.7 came out as the best-performing Claude model for enterprise document analysis.
Creative and Design Work
One team simply said: “Claude Opus 4.7 is the best model in the world for building dashboards and data-rich interfaces. The design taste is genuinely surprising. It makes choices I would actually ship.” That kind of feedback, coming from a design-focused team, signals something about the model's improved professional taste in creative output.
The Cybersecurity Angle: Something Worth Knowing
Last week, Anthropic published something called Project Glasswing, which focused on the risks and benefits of AI models in cybersecurity. They announced that their most powerful model, Claude Mythos Preview, would stay limited while they tested new safety measures on less capable models first.
Opus 4.7 is that first test case.
Anthropic explicitly worked during training to reduce certain cyber capabilities in Opus 4.7 compared to Mythos Preview. The model also ships with safeguards that automatically detect and block requests related to prohibited or high-risk cybersecurity uses.
At the same time, they are not shutting out legitimate security professionals. Anthropic launched a new Cyber Verification Program for security researchers, penetration testers, and red-team professionals who want to use the model for legitimate work. What Anthropic learns from real-world deployment of these safeguards will feed into their eventual plan for a broader release of Mythos-class models.
This is a practical example of safety being built into a release process rather than bolted on as an afterthought.
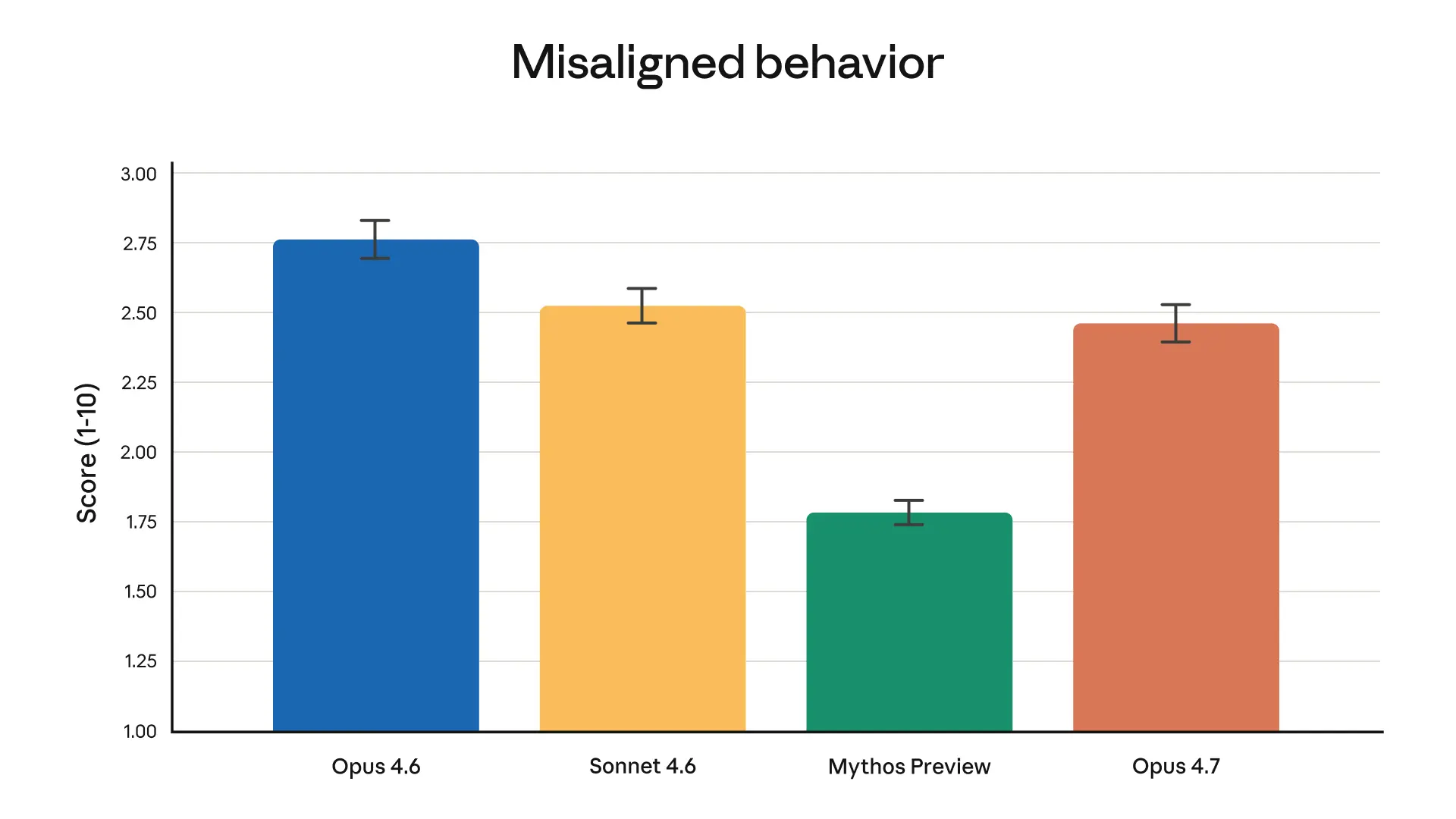
Safety and Alignment: Honest Reporting
Anthropic is unusually transparent about their safety evaluations, and the Opus 4.7 release continues that pattern.
Overall, Opus 4.7 shows a similar safety profile to Opus 4.6. Evaluations show low rates of deception, sycophancy, and cooperation with misuse. On honesty and resistance to malicious prompt injection attacks, Opus 4.7 is an improvement.
Where it is slightly weaker: the model shows a modest increase in giving overly detailed harm-reduction advice on controlled substances.
Their alignment assessment concluded that the model is “largely well-aligned and trustworthy, though not fully ideal in its behavior.” For reference, Mythos Preview still holds the top spot in their alignment evaluations.
All of this is documented in the Claude Opus 4.7 System Card, which is publicly available.
New Features Launching Alongside Opus 4.7
Beyond the model itself, Anthropic is shipping several features at the same time.
More Effort Control
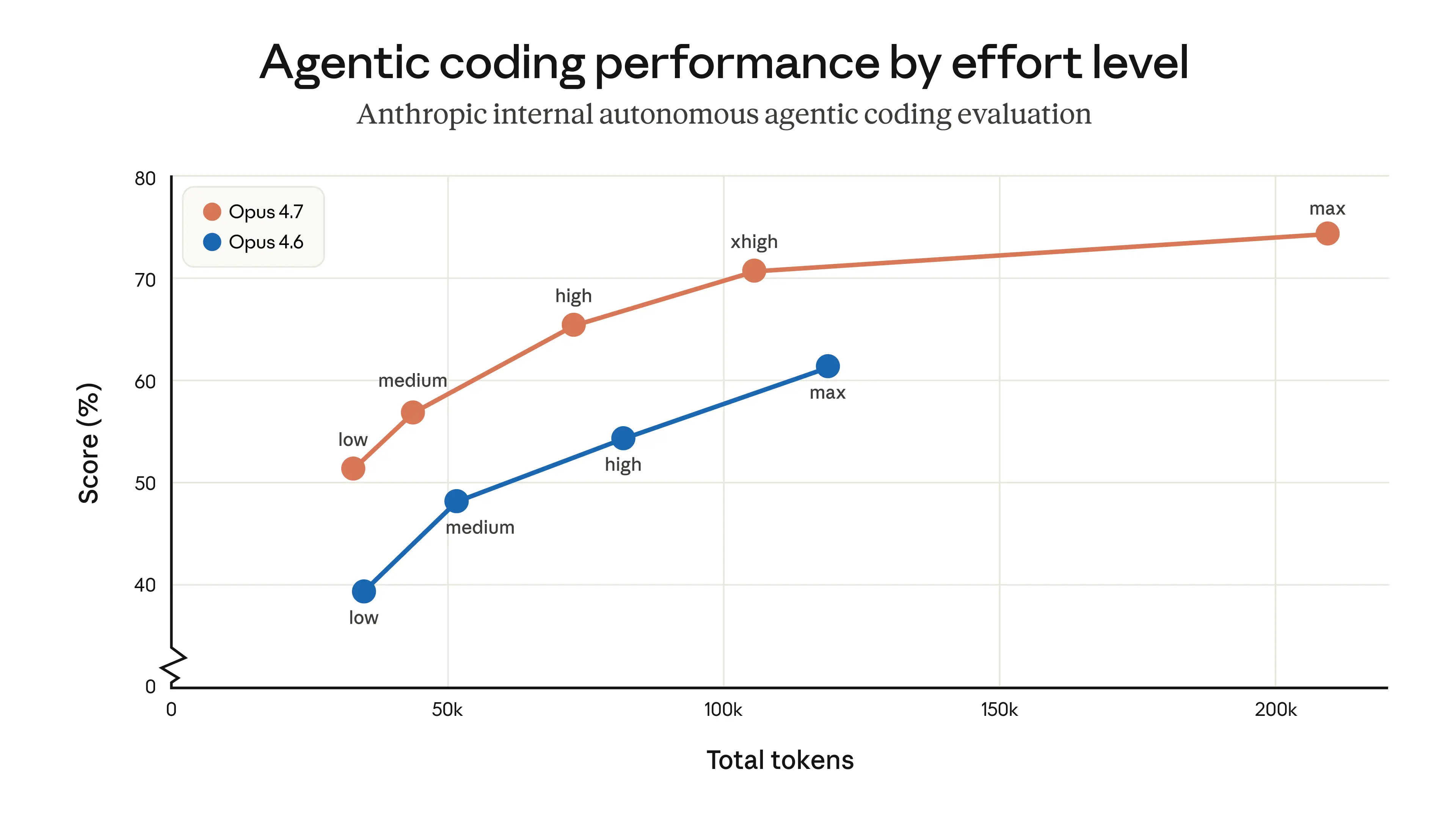
Opus 4.7 introduces a new effort level called “xhigh,” sitting between the existing “high” and “max” settings. This gives developers finer control over the tradeoff between how deeply the model reasons and how long it takes to respond. In Claude Code specifically, Anthropic has raised the default effort level to xhigh for all plans. If you are testing Opus 4.7 for coding or agentic work, starting at high or xhigh is the recommended approach.
Task Budgets on the API (Public Beta)
Developers building on the Claude API now have access to task budgets in public beta. This lets you guide how the model spends its token budget across a longer run, helping it prioritize work sensibly rather than burning through tokens on early steps and losing quality at the end.
New Claude Code Features
Two notable additions are coming to Claude Code:
The first is the /ultrareview slash command, which triggers a dedicated review session. The model reads through your changes and flags bugs and design issues that a careful human reviewer would catch. Pro and Max users get three free ultrareviews to try it out.
The second is an expansion of auto mode to Max users. Auto mode lets Claude make decisions on your behalf during longer tasks, which means fewer interruptions and smoother execution of complex workflows. Anthropic designed this to give users more control over when the model pauses for input, without requiring you to manually approve every small action.
What to Think About Before Migrating
If you are currently running Opus 4.6 and thinking about upgrading, here are the practical things worth knowing.
Token Usage Has Changed
Two factors affect token usage in Opus 4.7. First, the model uses an updated tokenizer. The same input might map to more tokens, roughly 1.0 to 1.35 times more depending on content type. Second, at higher effort levels, especially on later turns in agentic settings, the model produces more output tokens because it thinks more carefully.
Anthropic says their own internal testing shows favorable net results on a coding evaluation, but they recommend measuring the actual difference on your real traffic before assuming things will be cheaper.
Controlling Costs
You have a few tools available. The effort parameter lets you dial back reasoning depth. Task budgets help you cap token spend across a run. And prompting the model to be more concise is always an option.
Prompts Need a Review
Because Opus 4.7 follows instructions more literally, prompts written for earlier models might behave differently now. If something you have been running for a while starts producing unexpected results after switching models, review the prompt rather than assuming the model is broken. Anthropic has published a migration guide with specific advice on this.
The Bigger Picture: Where This Fits
It is worth stepping back for a second and thinking about what Opus 4.7 represents in context.
We are in a period where AI models are getting noticeably better at doing real work over long periods of time, without constant human correction. The improvements in Opus 4.7, particularly around autonomous coding, memory, instruction following, and error recovery, all point in the same direction: AI agents that can be trusted with harder tasks and longer timelines.
That is not hype. Multiple independent teams, working on very different problems, are describing the same experience: the model works harder, stops less, and gets more things right the first time.
At the same time, Anthropic is being thoughtful about where they deploy capabilities and how they manage the risks that come with more powerful models. The Cyber Verification Program and the Mythos Preview release strategy show a company genuinely thinking about the difference between models that are more capable and models that are safer. Those do not have to be in opposition.
Should You Try It?
If you are a developer, yes. Especially if your work involves:
- Complex multi-step coding tasks
- Long agentic workflows where reliability matters
- Document analysis and reasoning
- Anything that involves reading or interpreting detailed images
- Legal, financial, or technical research
If you are a general user curious about what the Claude models can do, Opus 4.7 is available now through Claude products. You can try it directly and see the difference for yourself.
If you are coming from Opus 4.6, the migration path is straightforward but worth planning for. Read the migration guide, check your prompts, and test on real traffic before going all-in.
A Final Thought
Opus 4.7 feels like the kind of release that might not get as much mainstream attention as a major product launch, but matters more in practice. It is the model that makes real work smoother, catches more mistakes, follows instructions properly, and earns trust by being honest when it does not know something.
That combination of reliability, honesty, and genuine capability improvement is rarer than it sounds. It is also exactly what people who depend on AI tools every day are looking for.
Anthropic is building in public, sharing their safety findings, inviting feedback through verification programs, and making it easy for developers to test and migrate. That kind of transparency, combined with a model that actually performs at this level, is worth paying attention to.
Claude Opus 4.7 is available now. You can learn more at https://www.anthropic.com/news/claude-opus-4-7
More Posts:
- ElevenLabs Voice Isolation Explained, Full Tutorial and Review
- Liquid AI Launches LFM2.5-350M, Compact AI Model Trained on Massive 28T Token Dataset
- Stop Windows From Sharing Your Internet, Turn Off This Hidden Setting for Faster Speeds
- How Clientforce Automates Your Sales Process From First Contact to Closed Deals
- Traffic Magnets: How Simple Tools Can Generate 10,000+ Monthly Buyer Clicks From Google