American AI Startup Poolside Releases Laguna XS.2, a Free High-Performance Open Model for Local Agentic Coding

American AI Startup Poolside Releases Laguna XS.2, a Free High-Performance Open Model for Local Agentic Coding
There's something exciting happening in AI right now, and it's not coming from the usual suspects.
Most of the headlines about AI coding assistants go to the big names: OpenAI, Google, Anthropic. But last week, a smaller San Francisco-based startup called Poolside quietly dropped something that deserves a lot more attention than it's getting. They released not one but two new AI models, a suite of developer tools, and an open-weight model that you can literally run on your laptop, for free, offline, with no strings attached.
That model is called Laguna XS.2, and if you care about coding, AI, or just not paying for cloud subscriptions, you're going to want to know about it.
Who Is Poolside, and Why Should You Care?
Before getting into the technical details, let's talk about who Poolside actually is.
The company was founded in San Francisco in 2023. They're not as well-known as OpenAI or Mistral, and they haven't flooded Twitter with hype campaigns. But what they've been quietly doing is building AI models from the ground up with one very specific thing in mind: software development.
Most AI labs treat coding as one feature among many. Poolside treats it as the feature. Their core belief is that software development is the best proxy for general intelligence. Think about it, writing code requires planning across long time horizons, solving abstract problems, debugging edge cases, and coordinating many moving parts at once. If an AI can truly master software engineering, it's demonstrating a kind of thinking that's very close to how humans reason through hard problems.
That philosophy shapes everything they build. Their models aren't general-purpose chatbots with a coding plugin bolted on. They're purpose-built reasoning systems trained specifically to write, debug, and execute code the way a real software engineer would.
Poolside also has a history of serving government and public sector clients, organizations that need AI deployed in high-security, air-gapped environments where cloud connectivity isn't an option. That background has pushed them to build models that are genuinely powerful without needing an internet connection, which turns out to be pretty valuable for a lot of other people too.
The Big Release: Two Models and Two Products
On launch day, Poolside released four things at once:
The models:
- Laguna M.1: their flagship, a 225-billion parameter model built for the most demanding agentic coding tasks
- Laguna XS.2: a smaller, open-weight model built for local use, free for anyone to download
The products:
- Pool: a terminal-based coding agent that connects directly to the Laguna models
- Shimmer: a web-based, mobile-friendly coding environment where you can build apps and APIs using the Laguna models on the go
This was Poolside's first time releasing anything to the public. Before this, they existed almost entirely in private. The fact that they're entering the public space with both a frontier-tier closed model and a fully open-source local model at the same time says a lot about how they see the AI landscape.
What Exactly Is Laguna XS.2?
Here's where things get interesting.
Laguna XS.2 is a 33-billion parameter Mixture-of-Experts (MoE) model with only 3 billion active parameters per token. It was trained on over 30 trillion tokens of data and is available for free on Hugging Face under the Apache 2.0 license: one of the most permissive open-source licenses there is.
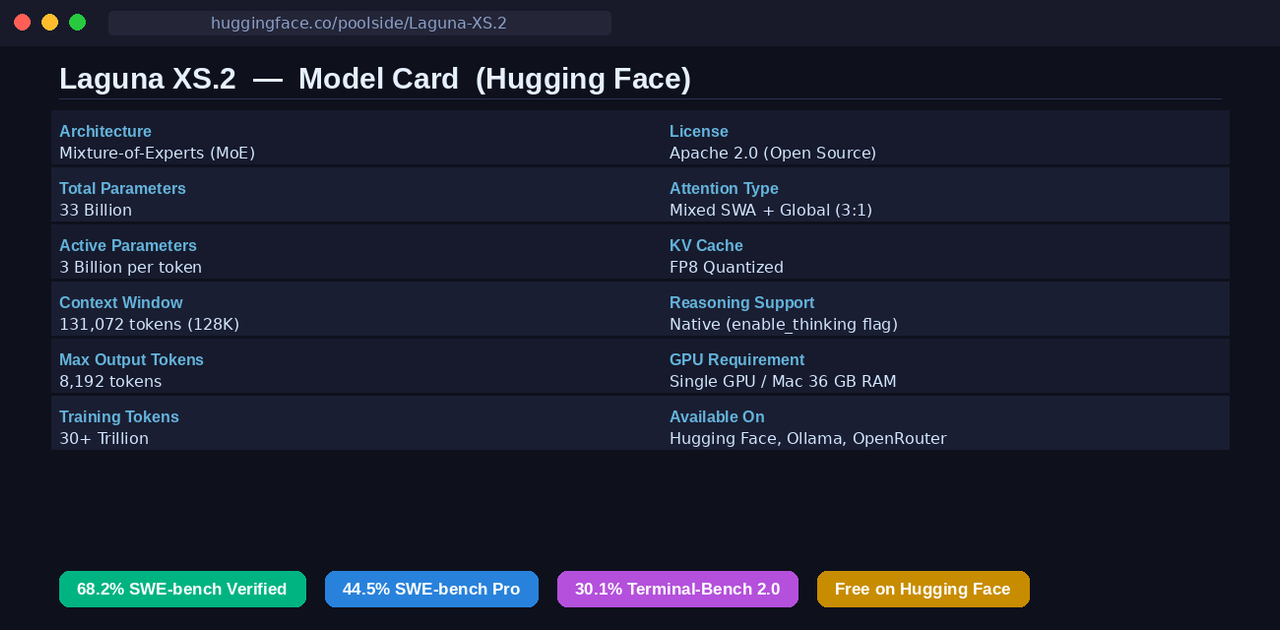
If those numbers feel abstract, here's what they mean in practice:
Mixture of Experts: Doing More with Less
A standard AI model like GPT-4 activates all of its parameters every time it processes a token (a word or piece of a word). That's expensive. It requires a lot of compute, a lot of memory, and usually a lot of hardware.
A Mixture-of-Experts model works differently. Instead of one giant network that handles everything, it has many specialized “expert” sub-networks. When processing each token, it only activates the most relevant experts, not all of them. Laguna XS.2 has 33 billion total parameters, but only 3 billion are active at any given moment.
The result is a model that has the capability of something much larger, but runs with the efficiency of something much smaller. That's why it can run on a single GPU, or even on a Mac with 36 GB of RAM using Ollama.
Sliding Window Attention: Staying Fast at Scale
One of the main bottlenecks for AI models processing long documents or codebases is something called the “KV cache”, a memory structure that stores information about every token the model has seen. As the context grows, so does the KV cache. This can quickly max out your GPU memory.
Laguna XS.2 addresses this with an architecture that mixes Sliding Window Attention (SWA) and global attention layers in a 3:1 ratio across its 40 layers. In 30 of those layers, each token only attends to a local window of 512 nearby tokens rather than the entire sequence. This dramatically cuts memory usage and makes inference faster without significantly hurting the model's ability to reason across long contexts.
It also stores the KV cache in FP8 format, a more compressed data type, which further reduces memory per token.
Despite these optimizations for efficiency, the model still supports a 131,072-token context window, which means it can hold and reason about roughly 100,000 words at once. That's enough to fit an entire medium-sized codebase in a single conversation.
Native Reasoning and Tool Calling
This isn't just a text generator. Laguna XS.2 was built to be an agent, a system that can plan, reason, use tools, and execute multi-step tasks autonomously.
It has native reasoning support built in. When you enable the enable_thinking flag, the model can emit “thinking” blocks between tool calls, essentially letting you see its internal reasoning process as it works through a problem. This isn't just for transparency, it makes the model more accurate on hard tasks because it's forced to slow down and plan before acting.
It also supports structured tool calling natively, which means it can interact with external systems, run code, call APIs, and take actions in the real world, not just generate text and hope for the best.
The Benchmarks: How Does It Actually Perform?
Let's talk numbers.
Laguna XS.2 hits 68.2% on SWE-bench Verified: a standard industry benchmark that tests an AI's ability to solve real GitHub issues from popular open-source repositories. It scores 62.4% on SWE-bench Multilingual (across multiple programming languages), 44.5% on SWE-bench Pro (a harder variant of the benchmark), and 30.1% on Terminal-Bench 2.0 (a test of the model's ability to complete tasks directly in a terminal environment).
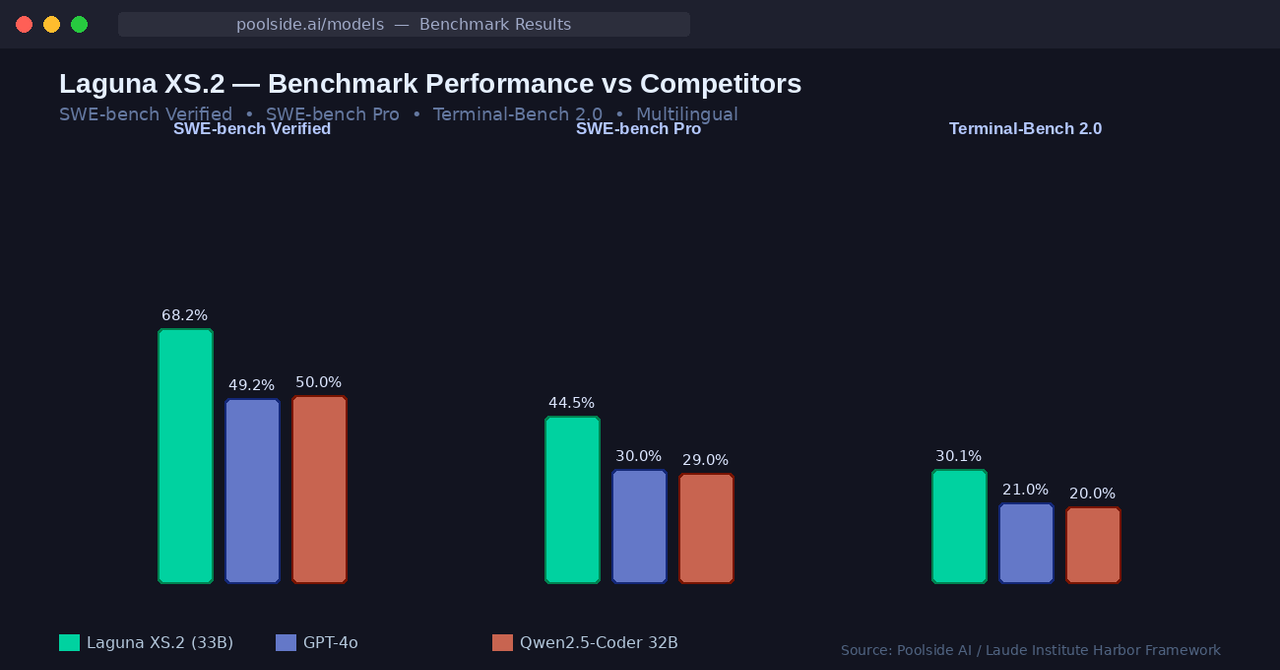
What makes these numbers impressive isn't just the absolute scores, it's the efficiency of achieving them.
Most models that hit this level of performance on SWE-bench are much larger and require significantly more compute. Laguna XS.2 reaches near-frontier performance with just 3 billion active parameters per token. For context, GPT-4o, a model from a company with vastly more resources, scores around 49% on SWE-bench Verified. Laguna XS.2 beats it with a fraction of the active compute.
That's not magic. It's the result of extremely careful training, something Poolside has spent years developing.
How Poolside Trains These Models
One of the most interesting parts of Poolside's release was the transparency they brought to the training process. Here's a simplified breakdown of how they actually built Laguna XS.2.
The Model Factory
Poolside built what they call a “Model Factory”, an internal platform that handles all aspects of model training, from architecture experiments and data mixing to reinforcement learning and evaluation. Before it existed, experiments that used to take weeks to set up could now run in under an hour. That kind of iteration speed matters a lot when you're trying to train increasingly capable models.
AutoMixing: Getting the Data Right
What data you train on matters as much as how much you train. Poolside developed something called AutoMixer, which automatically finds the optimal mix of training data.
Instead of human engineers manually guessing how much code versus math versus general text to include, AutoMixer trains around 60 smaller “proxy” models, each on a different data mix. It then measures their performance across key capability groups, code, math, STEM, and common sense reasoning, and uses those results to build a learned model of how data composition affects final performance. Then it optimizes that mapping to find the best mix for the main training run.
The approach is inspired by prior academic work on data selection, but Poolside adapted it with richer data groupings and applied it at scale.
Reinforcement Learning in a Virtual Gym
After pre-training on raw data, the model goes through a reinforcement learning phase that's unlike what you see in most language models.
Poolside uses asynchronous, on-policy agent RL: a fully custom system where the model is deployed as an actual agent that solves real software engineering tasks in sandboxed environments. Each task runs in an isolated container with limited RAM and CPU. The model writes code, runs tests, and receives feedback based on whether its code actually works. No partial credit for almost-right answers.
The training system runs continuously: actor processes pull tasks from a dataset, spin up containers, run the agent against each task using the latest model checkpoint, and write the results to storage. The trainer continuously reads those results and updates the model weights, all asynchronously, so inference and training are always happening in parallel.
This is a much harder way to train a model, but it's also why Laguna XS.2 is unusually good at completing real coding tasks rather than just generating plausible-looking code that doesn't compile.
Running It Locally: What You Actually Need
This is the part most people want to know about. Can you actually run this on your own machine?
Yes. Here are the ways to do it:
Ollama (easiest):
ollama launch pool --model laguna-xs.2
Ollama has native support for Laguna XS.2 with MLX acceleration on Apple Silicon Macs. If you have 36 GB of unified memory, this is the recommended path.
vLLM (for GPU servers):
vllm serve \
--model poolside/Laguna-XS.2 \
--tool-call-parser pool
This is best if you have an NVIDIA GPU with enough VRAM to load the model. Laguna XS.2 support has been merged into vLLM and will ship in the next release.
Hugging Face (weights only): Download the weights directly from huggingface.co/poolside/Laguna-XS.2 and run it with Transformers or any compatible inference stack.
The model also integrates with Zed and JetBrains editors through the pool agent, so you can use it as a coding assistant directly inside your IDE without leaving it to open a terminal.
The Two Products: Pool and Shimmer
Beyond the model weights, Poolside shipped two products designed to make the Laguna models easier to use.
Pool: Your Terminal-Based Coding Agent
Pool is a lightweight terminal agent and Agent Client Protocol (ACP) server. It's the same agent harness that Poolside uses internally for training and evaluation, now available as a research preview.
You install it with a single command:
curl -fsSL https://downloads.poolside.ai/pool/install.sh | sh
Once it's running, you can give it natural language instructions in your terminal and it will write code, run tests, inspect errors, and iterate, all autonomously. It uses the ACP (Agent Client Protocol) standard, which means it can connect to any compatible client, not just Poolside's own interface.
Shimmer: Code Anywhere, Even on Mobile
Shimmer is a web-based coding environment with a twist, it's optimized for mobile. You can use it to build web apps, APIs, and command-line tools using the Laguna models from your phone or tablet.
Each Shimmer session gives you an instant-on virtual machine with the Poolside agent preinstalled. You describe what you want, and the agent builds it, runs it, and shows you the result, all in the browser, all without any local setup.
For students and developers who don't always have a laptop nearby, this could genuinely be useful.
Free Access: What's the Catch?
There kind of isn't one, for now.
Laguna XS.2 is free forever under Apache 2.0. You download the weights, you run them wherever you want, you can fine-tune them, quantize them, build commercial products with them, Apache 2.0 allows all of that without royalty payments or special agreements.
Laguna M.1 is different. The weights are proprietary, but Poolside is offering free API access for a limited time through their platform and through OpenRouter. If you're a small team at a startup or a researcher at a university, Poolside has also said they'll raise rate limits or even share the M.1 weights on request.
The play here seems to be getting developers hooked on the ecosystem while the company continues to grow its commercial client base in government and enterprise.
Why This Matters: The Open West
There's a bigger point worth making about why this release matters beyond just the technical specs.
The AI world has a geography problem. Most of the open-weight models that power the global developer ecosystem come from China, models like DeepSeek and Qwen. They're excellent. But for governments, enterprises, and researchers in the West who have concerns about supply chain, data policy, or geopolitical risk, relying entirely on Chinese-origin weights creates a real dependency.
Poolside is explicit about this. Their blog post says plainly that “the West needs strong open-weight models” and that releasing Laguna XS.2 is part of their commitment to building that ecosystem.
That's a meaningful statement. If Laguna XS.2 gets adopted widely, fine-tuned by researchers, integrated into tools, and built into the next generation of applications, Poolside will have created a Western alternative that's genuinely competitive, not a second-tier fallback.
Who Should Actually Try This?
Here's a practical breakdown of who gets the most out of Laguna XS.2:
Students and self-taught developers. If you're learning to code and want an AI assistant that can actually run autonomously on your machine, this is now free. No subscriptions. No usage limits. No API keys.
Privacy-conscious developers. Because the model runs entirely offline, nothing you type ever leaves your machine. For anyone building something sensitive or just uncomfortable with cloud-based coding assistants, local models are the answer.
Researchers and fine-tuners. Apache 2.0 means you can fine-tune Laguna XS.2 on your own data, create specialized variants, and distribute them commercially. That's a huge deal for anyone building domain-specific coding tools.
Mac users with Apple Silicon. The Ollama path with MLX support is specifically optimized for Macs. If you have an M-series chip with 36 GB of unified memory, you have enough to run a frontier-competitive coding model natively.
Teams evaluating open alternatives. If your company has been using a closed API and wondering what open alternatives look like in 2026, Laguna XS.2 is a legitimate answer.
How Laguna XS.2 Compares to Other Open Models
The open-source AI model space has exploded in the last two years. There are now dozens of capable models you can run locally. So how does Laguna XS.2 actually stack up?
The most obvious comparisons are to Qwen2.5-Coder 32B from Alibaba and DeepSeek Coder V2, two of the most popular open-weight coding models in the developer community right now. Both are excellent models, both are free to use, and both run locally.
Where Laguna XS.2 pulls ahead is specifically in agentic performance. Most open models were evaluated primarily on code generation benchmarks, tasks where the model is shown a problem and asked to write code to solve it in one shot. Laguna XS.2 was evaluated and trained specifically for multi-step agent workflows, tasks where the model needs to plan across many steps, use tools, read outputs, and iterate based on what it finds.
SWE-bench is a good illustration. It doesn't ask the model to write code from scratch. It gives the model an actual GitHub repository with a broken issue and asks it to navigate the codebase, understand the problem, write a fix, and verify it works. That's much closer to what a real developer does day-to-day than a standalone “write a function that does X” prompt.
Laguna XS.2's 68.2% on SWE-bench Verified puts it ahead of most open models at comparable or even larger sizes. Qwen2.5-Coder 32B, for reference, scores around 50% on the same benchmark, and it has more active parameters.
The other important differentiator is the ecosystem. Laguna XS.2 comes with a purpose-built agent harness (Pool), native ACP support for connecting to other tools, and a cloud sandbox (Shimmer) for mobile development. Most open models arrive as weights and let you figure out the infrastructure yourself. Poolside is trying to ship the whole stack.
Whether that's enough to displace the community momentum behind Qwen and DeepSeek among hobbyist developers remains to be seen. But for teams building production agentic applications who want an open alternative they can fine-tune and deploy on their own infrastructure, Laguna XS.2 is a strong option that didn't exist three months ago.
What Apache 2.0 Actually Means for You
The license matters more than most people realize, so it's worth taking a minute on this.
Apache 2.0 is one of the most permissive open-source licenses available. Here's what it specifically allows you to do with Laguna XS.2:
- Run it privately: on your own hardware, air-gapped, with no reporting to Poolside
- Fine-tune it: train it on your own data to create a specialized variant
- Quantize it: compress it into smaller formats (like GGUF) for even lighter local use
- Build commercial products with it: ship a product powered by Laguna XS.2 and charge money for it, without paying royalties
- Distribute it: share the weights or your fine-tuned version with others
The only thing Apache 2.0 really requires is that you include the original license notice when distributing. That's it.
Compare that to some other model licenses that restrict commercial use, require permission for certain fine-tuning scenarios, or include clauses about not competing with the original company. Apache 2.0 has none of those restrictions.
For developers building tools, for startups embedding AI into their products, and for researchers who want to use the model as a foundation for academic work, this licensing choice is a genuine gift.
The Bigger Picture: What's Next for Poolside?
Poolside has been clear that this is just the beginning.
They've committed to continued progress in the open ecosystem and plan to scale up the Laguna model family over time. Laguna XS.2 was trained from scratch in just five weeks after M.1 finished pre-training, that's a fast iteration cycle. If they keep that pace, the next generation of XS models could arrive quickly.
They've also mentioned releasing a Laguna XS.2-base version soon, specifically for practitioners who want a clean starting point for fine-tuning without post-training behaviors baked in.
The Model Factory infrastructure they've built, with its automated data mixing, async reinforcement learning, and rapid experiment cycles, gives them the engineering foundation to keep improving. The real question is whether the developer community embraces the model and starts pushing it in directions Poolside hasn't anticipated.
That's usually when things get interesting.
Conclusion: This Is Worth Paying Attention To
A few years ago, the idea that you could run a competitive AI coding agent on your laptop for free, one trained with reinforcement learning on 30 trillion tokens, with a 128K context window and native tool calling, would have seemed like science fiction.
Now it's a Tuesday afternoon announcement from a startup most people haven't heard of.
Laguna XS.2 isn't perfect. It's not going to replace every cloud API for every use case. But it's a serious model released under a serious license by a team that clearly knows what they're doing.
If you have a Mac with 36 GB of RAM, a Linux box with a decent GPU, or even just a Hugging Face account and some patience, you can run state-of-the-art agentic coding AI right now, locally, privately, and completely free.
That's worth trying. Go download the weights.
Model weights available at huggingface.co/poolside/Laguna-XS.2. Pool agent available at poolside.ai. Free API access via OpenRouter (limited time).
More Posts:
- How to Start Flipping Domains with Zero Experience Using AIFlipDomains
- Codex, Claude Code, and Copilot Were All Breached — Attackers Targeted Credentials, Not AI Models
- OpenMOSS Introduces MOSS-Audio: A New Open-Source Model for Speech and Sound Intelligence
- InvoiceFlow Review: The Best Invoice Tool for Beginners?
- Google Unveils Simula: A Reasoning-Centric System for Building Controllable, Scalable Synthetic Datasets Across Specialized AI Fields