OpenMOSS Introduces MOSS-Audio: A New Open-Source Model for Speech and Sound Intelligence

By the time you finish reading this, you'll understand why MOSS-Audio matters, what it actually does, and why the AI community is paying close attention to it.
OpenMOSS Introduces MOSS-Audio: A New Open-Source Model for Speech and Sound Intelligence
Why Understanding Audio Is a Genuinely Hard Problem
Think about the last podcast you listened to. A lot was happening in that audio file, more than you probably consciously registered.
You heard words, sure. But you also picked up on the speaker's mood from the tone of their voice. You noticed when they laughed, when they sounded uncertain, and when they spoke with confidence. If there was background music, you absorbed the atmosphere it created. If someone coughed in the background, your brain flagged it briefly and moved on. And if someone asked you “what did the host say around the 15-minute mark?”, you could probably scroll back and find it.
Doing all of that, automatically and computationally, is a genuinely hard problem.
For years, the AI field's answer to this was to build a bunch of separate, specialized tools, one for transcribing words, another for recognizing speakers, another for detecting emotions, another for analyzing music. You'd chain them all together, and hope the outputs made sense when combined. The process was messy, error-prone, and expensive.
A team from OpenMOSS, MOSI.AI, and the Shanghai Innovation Institute decided to tackle this differently. Their release, called MOSS-Audio, packages all of those capabilities into a single open-source foundation model. One model. All the tasks.
That sounds simple. The architecture behind it is anything but.
What MOSS-Audio Can Actually Do
Before getting into the technical details, let's be clear about what this model is actually capable of in practice, because the list is longer than you might expect.
Speech and Content Understanding
This is the most obvious capability. MOSS-Audio can transcribe spoken words accurately, but it goes well beyond basic speech-to-text. It supports both word-level and sentence-level timestamp alignment, meaning it can tell you not just what was said, but when it was said in the audio file. That might sound minor, but for applications like meeting summarization or legal transcription, precise timing is the difference between useful and useless.
The model handles dialects, accents, code-switching (when speakers mix languages mid-sentence), and even singing. It's been evaluated across 12 different ASR dimensions, and its error rates consistently beat competitors.
Speaker and Emotion Analysis
MOSS-Audio can identify characteristics of the person speaking, and analyze their emotional state based on tone, timbre, and conversational context. Emotion detection from audio is notoriously difficult because the same words can carry completely different emotional weight depending on delivery. The model handles this by processing acoustic signals that text alone would miss.
Environmental Sound and Scene Understanding
This is where things get interesting beyond human speech. MOSS-Audio can identify background sounds, environmental noise, and non-speech acoustic signals, then use those to infer context. The sound of rain, traffic, a crowded restaurant, a hospital hallway. These cues can tell you a lot about what's happening in a recording, and MOSS-Audio can extract and interpret them.
Music Understanding
The model analyzes musical content, covering style, emotional progression, and instrumentation. This opens up applications in music recommendation, content moderation, and automated tagging of audio libraries.
Audio Question Answering and Summarization
You can ask MOSS-Audio direct questions about audio content: “What topics did the speaker cover?” or “How did the tone of the conversation shift?” It can also produce summaries of podcasts, meetings, and interviews. Think of it as the ability to query an audio file like a document.
Complex Reasoning Over Audio
This is the most advanced capability. Using a combination of chain-of-thought training and reinforcement learning, MOSS-Audio can perform multi-hop reasoning. That means answering questions that require connecting multiple pieces of information from across an audio file. “Did the speaker's confidence level change after the third question?” is the kind of query that requires listening, analyzing, and reasoning in sequence.
The Four Model Variants
OpenMOSS shipped four versions at launch. Understanding the differences between them helps you figure out which one fits a specific use case.
MOSS-Audio-4B-Instruct
This variant uses Qwen3-4B as its language model backbone, resulting in roughly 4.6 billion total parameters. The “Instruct” designation means it's been optimized for following direct instructions and producing structured, predictable outputs. If you're building a production pipeline where you need the model to reliably execute a specific task, an Instruct variant is usually the right choice.
MOSS-Audio-4B-Thinking
Same backbone size as above, but the “Thinking” variants are trained with stronger chain-of-thought reasoning capabilities. They're better at tasks that require working through a problem step by step. The trade-off is that they may produce more verbose outputs. For research, analysis, or any use case where accuracy matters more than speed, Thinking variants shine.
MOSS-Audio-8B-Instruct
Scaled up to Qwen3-8B as the backbone, bringing the total parameter count to approximately 8.6 billion. More capacity for language understanding. Still optimized for structured instruction-following.
MOSS-Audio-8B-Thinking
The flagship. Biggest model, best reasoning. This is the version that tops the benchmark charts. If you need maximum performance and have the compute to support it, this is where you start.
The naming convention is worth remembering: number indicates scale (4B or 8B base LLM), and the suffix indicates capability profile (Instruct for production reliability, Thinking for deep reasoning).
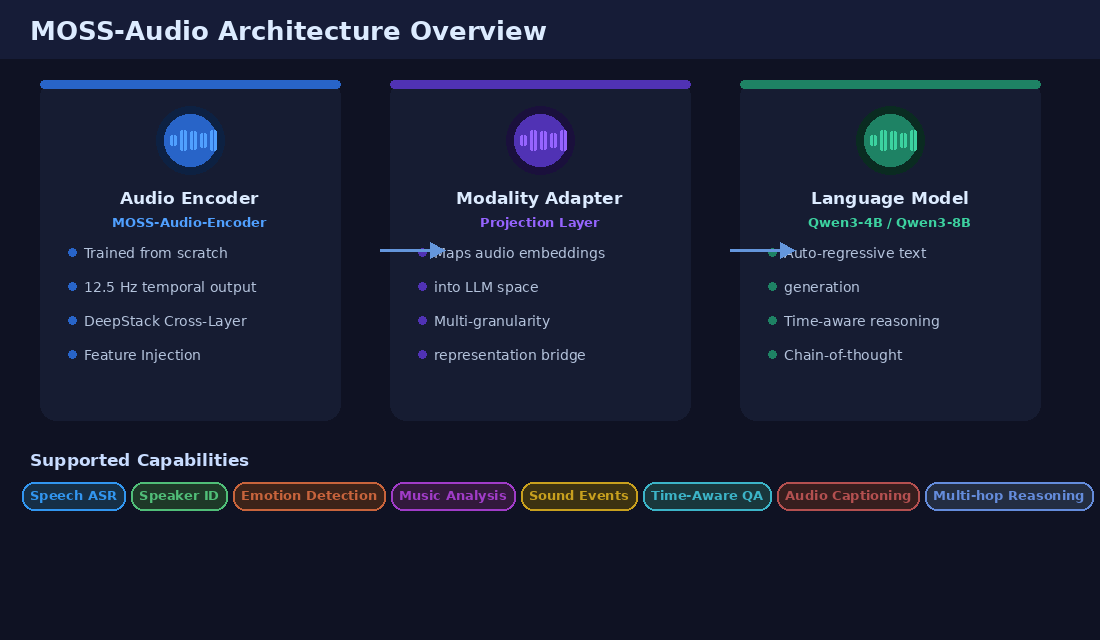
How the Architecture Works
One of the most interesting aspects of MOSS-Audio is the deliberate architectural choices the team made. This isn't a standard audio model with a language model glued on top. There are some genuinely clever design decisions here.
The Three Core Components
The architecture follows a modular three-part design:
An audio encoder sits at the front. Raw audio comes in, and the encoder converts it into continuous temporal representations at 12.5 Hz. This encoder was trained from scratch by the MOSS-Audio team rather than borrowed from existing systems. That decision matters, and we'll explain why in a moment.
A modality adapter sits in the middle. It takes the encoder's output, a representation of audio in encoder-space, and projects it into the language model's embedding space. This translation layer is what allows the LLM to “understand” audio the same way it understands text.
A large language model sits at the end. The projected audio representations are consumed by the LLM, which then generates text auto-regressively. The same LLM you'd use to generate language from text is now generating language from audio.
Why They Built the Encoder from Scratch
Most audio AI systems either use pre-existing audio encoders or adapt general-purpose audio models. The MOSS-Audio team made a conscious choice to train their encoder from the ground up.
Their reasoning: a purpose-built encoder delivers stronger speech representations, tighter temporal alignment with the actual audio signal, and better flexibility across acoustic domains. When you're optimizing for a model that needs to handle everything from whispered speech to heavy metal guitar to a crowded subway platform, a generalist encoder built specifically for that range outperforms an off-the-shelf component that was designed for narrower use.
This is a longer path to take during development, but it pays off in the downstream tasks.
Two Technical Innovations Worth Understanding
Two architectural innovations set MOSS-Audio apart from other audio language models. These aren't marketing bullet points. They're the mechanisms that make the model's performance possible.
DeepStack Cross-Layer Feature Injection
Here's a problem that shows up in a lot of audio models. When you take the output of an audio encoder, you typically take the final layer's output, the highest-level representation of what the encoder has learned. That high-level representation is semantically rich but has lost something in the process.
Think about it this way: the top layer of a deep encoder has abstracted away a lot of the low-level detail. It knows “this is an angry person speaking,” but it may have lost the precise acoustic fingerprints that carry information about, say, the subtle tremor in someone's voice, the exact pitch variation that indicates sarcasm, or the brief transient sound that tells you a door just closed in the background.
For many text tasks, losing that detail is fine. For audio, it's a real problem.
MOSS-Audio addresses this with something called DeepStack Cross-Layer Feature Injection. Rather than only feeding the encoder's final-layer output to the language model, the system also pulls features from intermediate layers of the encoder. These intermediate features are independently projected and then injected into the early layers of the language model.
The result is that the LLM receives a richer signal. It gets:
- High-level semantic understanding from the encoder's final layers
- Mid-level pattern recognition from intermediate layers
- Low-level acoustic details from earlier layers, things like rhythm, timbre, local time-frequency structure, and transient events
This multi-granularity approach means the language model isn't working from a single compressed summary of the audio. It's working from a layered representation that preserves detail at multiple scales. That's a meaningful advantage when the task involves subtle acoustic distinctions.
Time-Aware Representation Through Time-Marker Insertion
Language models are, by training and design, built for text. Text doesn't have an inherent temporal dimension in the same way audio does. Words follow each other sequentially, but there's no built-in representation of “this word happened at the 47-second mark.”
Audio absolutely has that dimension. And for a lot of audio tasks, that dimension is the whole point. “What was said in the first five minutes?” “What happened around the 2-hour mark of this meeting?” “Identify all instances where the speaker mentioned budget after the 10-minute point.” These are time-grounded questions, and standard language models aren't equipped to answer them.
The MOSS-Audio team solved this through a time-marker insertion strategy during pretraining. During training, explicit time tokens are inserted into the sequence of audio frame representations at fixed time intervals. These tokens are positional signals that tell the model where in time a given audio representation sits.
By training on sequences that include these time markers, the model learns to associate content with temporal positions. It doesn't just learn “what” was said or heard. It learns “what” in the context of “when.”
The result is that MOSS-Audio can answer time-grounded questions naturally, as part of its text generation process. There's no separate localization head, no post-processing pipeline, no hack applied after the fact. Temporal reasoning is baked into the model's core behavior.
This matters enormously for real-world applications: podcast search, long-meeting analysis, audio forensics, content moderation with timestamp reporting, and any scenario where you need to point to a specific moment in an audio file.
The Benchmark Numbers (And Why They Matter)
Numbers only tell a story if you know what they're measuring. Here's what the benchmarks actually show.
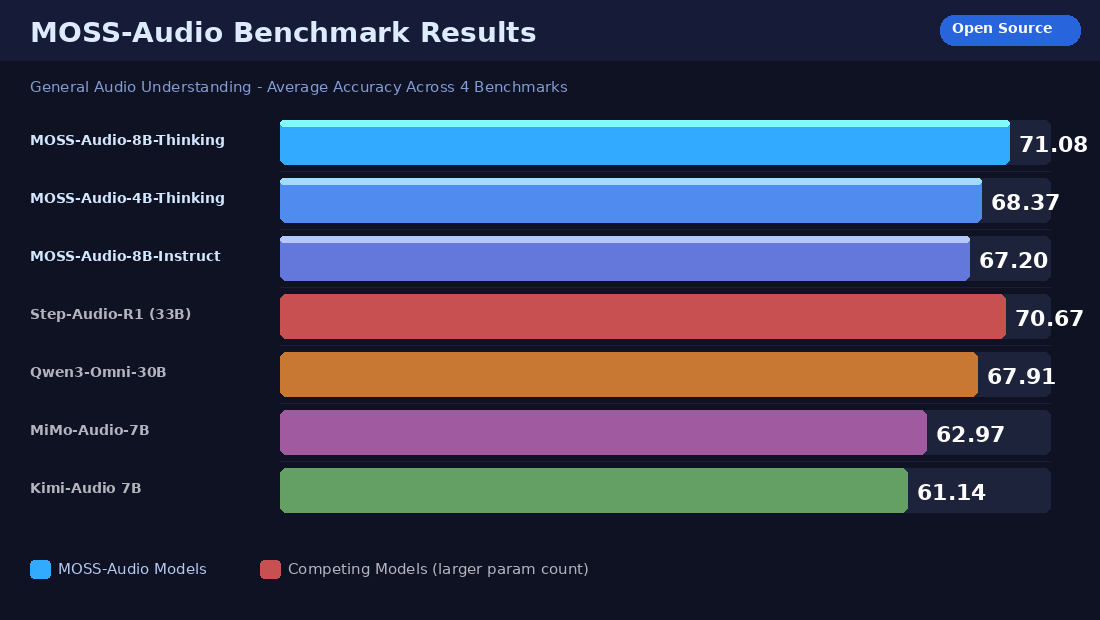
General Audio Understanding
The team evaluated MOSS-Audio-8B-Thinking across four benchmarks:
- MMAU: 77.33
- MMSU: 75.52
- MMAR: 66.53
- MMAU-Pro: 64.92
Average across all four: 71.08 accuracy.
For context, Step-Audio-R1 scores 70.67 on the same average, and that model has 33 billion parameters. MOSS-Audio-8B-Thinking achieves a higher score with approximately one-quarter the parameter count.
Qwen3-Omni-30B-A3B-Instruct, at 30 billion parameters, scores 67.91. Again, MOSS-Audio's 8.6B parameter model beats it.
The 4B Thinking variant scores 68.37. A model with 4.6 billion parameters outperforms competitors that are six to seven times larger.
That gap speaks to the quality of the architecture and the effectiveness of the training approach. Bigger isn't always better. Smarter training and cleaner design can punch well above weight.
Speech Captioning
The team used an LLM-as-Judge evaluation method across 13 distinct fine-grained dimensions:
Gender, age, accent, pitch, volume, speed, texture, clarity, fluency, emotion, tone, personality, and overall summary.
MOSS-Audio-8B-Instruct leads across 11 out of 13 of those dimensions, with an overall average score of 3.7252. That's a comprehensive victory in speech captioning, covering not just what was said but who said it and how.
Automatic Speech Recognition
On ASR spanning 12 evaluation dimensions, including health condition, code-switching, dialect, singing, and non-speech scenarios, MOSS-Audio-8B-Instruct achieves a Character Error Rate (CER) of 11.30. That's the lowest of all tested models.
CER measures how many character-level errors appear in a transcription. Lower is better. Achieving the lowest CER across 12 varied ASR categories suggests the model isn't just good at clean studio-quality speech. It handles the messy, real-world audio that production systems actually encounter.
What This Means for Developers and Researchers
If you're building something, this section is for you.
One Model Instead of a Pipeline
Before models like MOSS-Audio, building an audio-understanding application usually meant assembling a chain of specialized components. A Whisper-based ASR model for transcription, a separate speaker diarization system, a sentiment classifier, an audio event detector. Every addition to the chain adds latency, complexity, error propagation risk, and maintenance overhead.
MOSS-Audio collapses that chain into a single model. One inference pass can give you transcription, speaker characterization, emotion analysis, background scene understanding, and the ability to answer follow-up questions about the content. That's a meaningful simplification for production systems.
Open Source With Practical Weights
MOSS-Audio is open source, and the weights are available publicly. That means you can download, run, fine-tune, and build on top of this model without licensing restrictions. For researchers, that's standard. For product teams, it means no API dependency, no per-request billing, and the ability to deploy in environments where sending audio to an external API isn't acceptable.
The model and weights are available at the links below:
The 4B Variants Are Genuinely Useful
One thing worth emphasizing: you don't need the 8B model to get strong results. The 4B Thinking variant scoring 68.37 on general audio understanding while outperforming much larger models means developers working with limited GPU resources can still access competitive performance. That opens the door for deployment on consumer hardware, edge devices, and cost-constrained cloud setups.
Where MOSS-Audio Could Be Used in the Real World
Let's get concrete about applications, because “audio AI” can sound abstract until you put it in context.
Podcast and Media Intelligence
A media company with thousands of hours of archived audio content could use MOSS-Audio to make that content searchable, summarizable, and analyzable at scale. Instead of manual tagging or keyword search, you could query your entire archive with natural language questions. “Find all episodes where the host discussed interest rates after 2023.” The model handles the retrieval and reasoning.
Meeting and Call Analysis
Corporate teams spend enormous resources on meetings, and capturing the actual value of those conversations is a chronic problem. MOSS-Audio could power transcription, speaker-labeled summaries, emotion-tracking for customer calls, and time-stamped action item extraction. All from a single model, in a single pass.
Accessibility Tools
Real-time captioning, speaker identification for deaf users, and emotion flagging for people with social communication differences are all capabilities that could be built on MOSS-Audio. The model's ability to capture nuance beyond just words is particularly valuable here.
Content Moderation
Audio content on platforms needs to be reviewed for policy violations. MOSS-Audio's ability to detect emotional context, identify speakers, and analyze scene content could support more nuanced moderation systems that understand not just what's being said, but the context and tone in which it's being said.
Research and Academic Applications
For linguistics researchers, sociologists studying communication patterns, or anyone analyzing recorded human interaction at scale, MOSS-Audio offers a tool that can process and analyze audio with a level of sophistication that previously required significant multi-system infrastructure.
The Bigger Picture: What Open-Source Audio AI Is Becoming
There's a broader trend worth naming here.
For the past few years, large-scale AI capability has been concentrated in proprietary systems. The companies with the most compute and the largest teams have built the most capable models, and access to those models has been controlled through APIs, licensing agreements, and enterprise pricing.
Open-source releases like MOSS-Audio push back against that concentration. Not because open source is inherently better in every dimension, but because access matters. Research that requires API access to advance is slower and less democratically distributed than research that can run on hardware any graduate student can afford.
MOSS-Audio's benchmark numbers are particularly significant in this context. When an 8.6B parameter open-source model outperforms a 33B parameter proprietary model on standard benchmarks, it demonstrates that model efficiency and architectural quality can compensate for raw scale. That's a meaningful lesson for the field.
The team behind this model represents a collaboration between OpenMOSS, MOSI.AI, and the Shanghai Innovation Institute. They've chosen to release the model openly, with weights, code, and documentation available for anyone to use. That kind of release accelerates the entire field. Other researchers can build on it, identify its weaknesses, improve the training approach, and publish those improvements for everyone.
Limitations Worth Knowing About
MOSS-Audio is a strong model, but intellectual honesty requires acknowledging what it isn't.
It's a research release. Production deployment at scale requires engineering work around latency, throughput, error handling, and integration. The model exists and performs well on benchmarks, but benchmarks aren't production.
The model's time-aware reasoning is a significant innovation, but long-form audio analysis (hours of content) may still present challenges in terms of context length and computational cost. This is a limitation shared across the field, not unique to MOSS-Audio.
Multi-language support, while present in the ASR capabilities, should be verified against specific target languages before building applications that depend on it. Code-switching handling is included, but performance can vary across language combinations.
And like all models trained on data from the real world, MOSS-Audio will reflect biases present in its training data. Applications involving speaker profiling or emotion detection should be deployed with appropriate caution and human oversight.
How MOSS-Audio Compares to What Came Before
To appreciate where MOSS-Audio fits in the landscape of audio AI, it helps to think about what existed before it and what problems those earlier systems had.
The Whisper Era
OpenAI's Whisper model, released in 2022, was a breakthrough in automatic speech recognition. It handled multiple languages, worked well across accents, and was released open-source. For pure transcription, it's still widely used.
But Whisper does one thing: speech to text. It doesn't understand scene context, it can't analyze emotion, it has no concept of who is speaking, and it doesn't do music. It also has no temporal reasoning capability in the sense MOSS-Audio does. You get a transcript, and then you're on your own.
The Specialist Model Era
After Whisper, teams built specialized models to fill the gaps. Speaker diarization models to identify who's talking. Audio event detection models for background sounds. Sentiment classifiers trained on speech features. Music classifiers. These all solve real problems, but combining them in a production system creates its own problems.
Every model has its own input format, output format, and error mode. Errors in one model propagate to the next. Maintaining multiple models with different dependencies is an engineering burden. And none of these models actually understand audio in a unified way. They're each doing a narrow job in isolation.
The Multimodal LLM Era
The most recent wave before MOSS-Audio involved attaching audio encoders to large language models. Qwen-Audio, Gemini's audio capabilities, and other systems demonstrated that a language model could process audio if given the right input encoding. This was a real step forward.
The key difference with MOSS-Audio is depth of design. The team didn't just attach a standard audio encoder to an LLM and call it done. They built a custom encoder from scratch, added multi-layer feature injection, and trained the system with time-marker tokens that give it native temporal reasoning. Those design choices compound into a measurable performance advantage.
Training Approach: What Goes Into Making MOSS-Audio Work
Understanding a model's capabilities means understanding how it was trained. MOSS-Audio's training approach includes several components worth knowing about.
Chain-of-Thought Training
The Thinking variants of MOSS-Audio are trained with chain-of-thought reasoning supervision. This means the model is trained not just to produce the right answer, but to produce the reasoning steps that lead to the right answer.
For audio tasks, this matters more than it might sound. When answering a complex question about an audio file, the model needs to mentally walk through: what was said, by whom, with what tone, in what temporal sequence, and how those pieces connect to form an answer. Chain-of-thought training teaches the model to make that process explicit, which both improves accuracy and makes the model's reasoning inspectable.
Reinforcement Learning
MOSS-Audio also uses reinforcement learning as part of its training for complex reasoning capabilities. Reinforcement learning, in the context of language models, typically means training the model using reward signals that reflect whether its outputs are actually good, not just whether they match a training example.
For audio reasoning, this is valuable because the space of possible reasoning paths is wide. A model trained purely on supervised examples might learn to produce plausible-sounding reasoning without actually getting the right answer. Reinforcement learning pressure pushes the model toward outputs that are correct, not just fluent.
The Multi-Task Training Regime
The model was trained across the full range of tasks it's designed to handle: ASR, speaker analysis, emotion detection, audio captioning, music understanding, environmental sound interpretation, and time-grounded QA. This kind of multi-task training creates a model that benefits from shared representations across tasks.
The features that help the model understand emotion also help it understand speaker characteristics. The representations that enable scene understanding also contribute to audio captioning. Multi-task training produces models that are more than the sum of their task-specific training data.
Practical Setup: Getting Started with MOSS-Audio
If you want to actually use this model, here's a practical orientation to what that looks like.
The model is available through HuggingFace, which means you can load it using standard transformers-compatible tooling. The 4B variants will fit on a single consumer-grade GPU with 16-24GB VRAM. The 8B variants need more headroom, typically 40GB VRAM for comfortable inference, or you can use quantized versions.
The GitHub repository includes inference scripts, example notebooks, and documentation for the key use cases. For most audio tasks, you'd provide an audio file as input alongside a text prompt describing what you want (transcription, summarization, question answering, etc.), and the model produces a text response.
For production deployment, the Instruct variants are the better starting point. They produce more predictable output formats, which makes parsing and downstream processing more reliable. The Thinking variants are better suited for exploration, analysis, and situations where you want to understand the model's reasoning.
Fine-tuning is also possible. The open weights mean you can adapt the model to domain-specific audio, whether that's medical conversations, legal depositions, specific music genres, or any other specialized audio domain.
A Final Thought on What This Release Signals
What the OpenMOSS team has shipped is a meaningful step in audio AI. Not because it's the first model to attempt audio understanding, but because it does it with architectural clarity, competitive performance, and full openness.
The decision to train a custom encoder. The DeepStack feature injection that preserves low-level acoustic detail. The time-marker pretraining that bakes temporal reasoning into the model's core. These aren't accidental improvements. They're the result of thinking carefully about what audio AI needs to be genuinely useful.
For anyone building with audio, researching speech and sound, or just paying attention to where AI capability is heading, MOSS-Audio is worth your time. Go through the code, run the model, test it against your actual use cases. That's how you find out whether a benchmark number translates to real-world value.
The resources to do that are below. Both the HuggingFace collection and the GitHub repository are publicly accessible.
Model Weights and HuggingFace Collection: https://huggingface.co/collections/OpenMOSS-Team/moss-audio
Source Code and Documentation: https://github.com/OpenMOSS/MOSS-Audio
Audio AI has been one of the quieter frontiers of the broader AI wave, often overshadowed by image generation and language modeling. MOSS-Audio is part of what makes it worth watching now.
Published based on technical reporting from the OpenMOSS team, MOSI.AI, and the Shanghai Innovation Institute.
More Posts:
- InvoiceFlow Review: The Best Invoice Tool for Beginners?
- Google Unveils Simula: A Reasoning-Centric System for Building Controllable, Scalable Synthetic Datasets Across Specialized AI Fields
- The Ultimate Guide to Inference Caching for Large Language Models
- OpenAI Launches $100 ChatGPT Pro Plan with 5x Higher Codex Limits Than Plus
- What Is Search Box Optimization (SBO) and Why It’s the Next Big Thing in Digital Marketing