China’s GLM-5 Just Set a New Standard: How Z.ai’s Latest AI Model is Changing the Game with Record-Low Mistakes and Revolutionary Training

China's GLM-5 Just Set a New Standard: How Z.ai's Latest AI Model is Changing the Game with Record-Low Mistakes and Revolutionary Training
China's GLM-5 Just Set a New Standard: How Z.ai's Latest AI Model is Changing the Game with Record-Low Mistakes and Revolutionary Training
If you've been following the AI race, you know it's been heating up fast. But here's something that just dropped that might change everything: a Chinese AI startup called Zhupai (or z.ai if you're into shorter names) just released GLM-5, and it's kind of a big deal. Like, really big.
So what makes this model special? For starters, it's literally better at admitting when it doesn't know something than any other AI out there. Sounds simple, right? But in the world of AI, this is huge. Let me break down why GLM-5 matters, what makes it different, and whether this is something you should care about.
What is GLM-5 and Why Should You Care?
GLM-5 is what tech people call a “frontier large language model.” Think of it as one of those super-advanced AI systems like ChatGPT or Claude, but with some serious upgrades under the hood. Z.ai just launched it, and it's already making waves for a few reasons that actually matter in real life.
First off, this thing is open source with an MIT License. Translation: businesses can use it, modify it, and deploy it without worrying about getting locked into one company's ecosystem. That's pretty rare for AI models this powerful.
But here's the real kicker: GLM-5 scored a -1 on something called the AA-Omniscience Index. Don't let the technical name fool you. What this means is that GLM-5 is the best in the world at knowing when to say “I don't know” instead of making stuff up. That's a 35-point improvement over the previous version, which is absolutely massive.
Think about it this way: you know how sometimes you ask someone a question and they'll confidently give you a completely wrong answer instead of just admitting they don't know? AI models do that too. It's called “hallucinating” in the tech world. GLM-5 is the first model that's really, truly good at avoiding that trap. It beats Google's models, OpenAI's models, and even Anthropic's Claude when it comes to not BS-ing you.
The “Agent Mode” That Actually Does Your Work
Here's where things get interesting for anyone who's ever had to create a report, spreadsheet, or presentation. GLM-5 has something called “Agent Mode” built right in. This isn't just about answering questions in a chat box anymore.
You can literally give GLM-5 a prompt like “create a financial report for Q4” and it'll generate an actual Microsoft Word document (.docx), PDF, or Excel spreadsheet (.xlsx) that you can immediately use. Not just text that you have to copy and paste. Not just suggestions. An actual, ready-to-open file.
Need a sponsorship proposal for your club? GLM-5 can create the full document. Working on a complex spreadsheet with formulas and everything? It handles that too. This is the kind of stuff that usually takes hours of formatting and fiddling around, and GLM-5 just… does it.
The Price Tag That Makes Other Companies Nervous
Let's talk money because this is where GLM-5 really starts to look disruptive. The model costs about $0.80 per million input tokens and $2.56 per million output tokens. If that sounds like gibberish, here's what it means: this model is roughly 6 times cheaper than Claude Opus 4.6, which is one of the top competitors.
To put this in perspective, you could run GLM-5 six times for the same cost as running Claude Opus once. And we're not talking about a cheaper, worse model. GLM-5 competes with the best models out there on actual performance benchmarks.
Here's a quick comparison to show you what I mean:
Some of the cheapest options cost just a few cents per million tokens (models like Qwen 3 Turbo and Grok), but they don't perform nearly as well. The really powerful models like Claude Opus 4.6 cost $5 for input and $25 for output per million tokens. GPT-5.2 Pro is even more expensive at $21 and $168.
GLM-5 sits at $1 and $3.20, which puts it in the sweet spot: way cheaper than the top-tier proprietary models, but way more powerful than the budget options. That's what we call a “steal” in the tech world.
How They Built This Beast: The Tech Behind GLM-5
Alright, let's get into the nerdy stuff for a minute (I promise to keep it readable).
GLM-5 is absolutely massive. It grew from 355 billion parameters in the previous version to 744 billion parameters. Parameters are basically the building blocks that make AI models smart. More parameters generally mean the model can handle more complex tasks, though there's way more to it than just size.
The model uses something called Mixture-of-Experts architecture, which means it has 40 billion parameters active at any given time, even though the total model has 744 billion. Think of it like having a huge team of specialists, but only calling in the right experts for each specific job instead of making everyone work on everything.
To train this monster, z.ai fed it 28.5 trillion tokens. That's 28,500,000,000,000 pieces of text data. To give you some context, if you read one token per second without stopping, it would take you about 900,000 years to read that much data. Yeah.
The “Slime” Innovation: A Weird Name for a Smart Idea
Here's where z.ai got really creative. Training AI models this big usually hits a wall because of something called “long-tail bottlenecks.” Basically, when you're using reinforcement learning (a technique for teaching AI through trial and error), you end up waiting around a lot while the AI generates responses.
Traditional systems make everything wait in line, which wastes tons of time. Over 90% of training time was just sitting around waiting for the AI to finish generating stuff.
Z.ai created something called “slime” (yes, really, that's what they named it). It's an asynchronous reinforcement learning system that lets different parts of the training happen independently instead of waiting for everything to finish before moving forward.
The technical term for one of the key innovations is “Active Partial Rollouts” or APRIL. What this does is address the generation bottlenecks that normally eat up all your training time. Instead of everything being stuck in lockstep, slime lets trajectories generate independently, which means you can iterate way faster on complex tasks.
The framework is built on three main parts: a high-performance training module (powered by something called Megatron-LM), a rollout module that uses SGLang and custom routers for generating lots of data quickly, and a centralized Data Buffer that manages everything.
Why does this matter? Because it means z.ai can train models to do more complex, multi-step tasks without burning through ridiculous amounts of time and compute power. This is the kind of infrastructure that lets AI move from just chatting to actually engineering solutions.
To keep costs manageable when you're actually using GLM-5, they integrated something called DeepSeek Sparse Attention. This lets the model handle a 200,000 token context window (that's roughly equivalent to a 400-page book) while keeping costs way down.
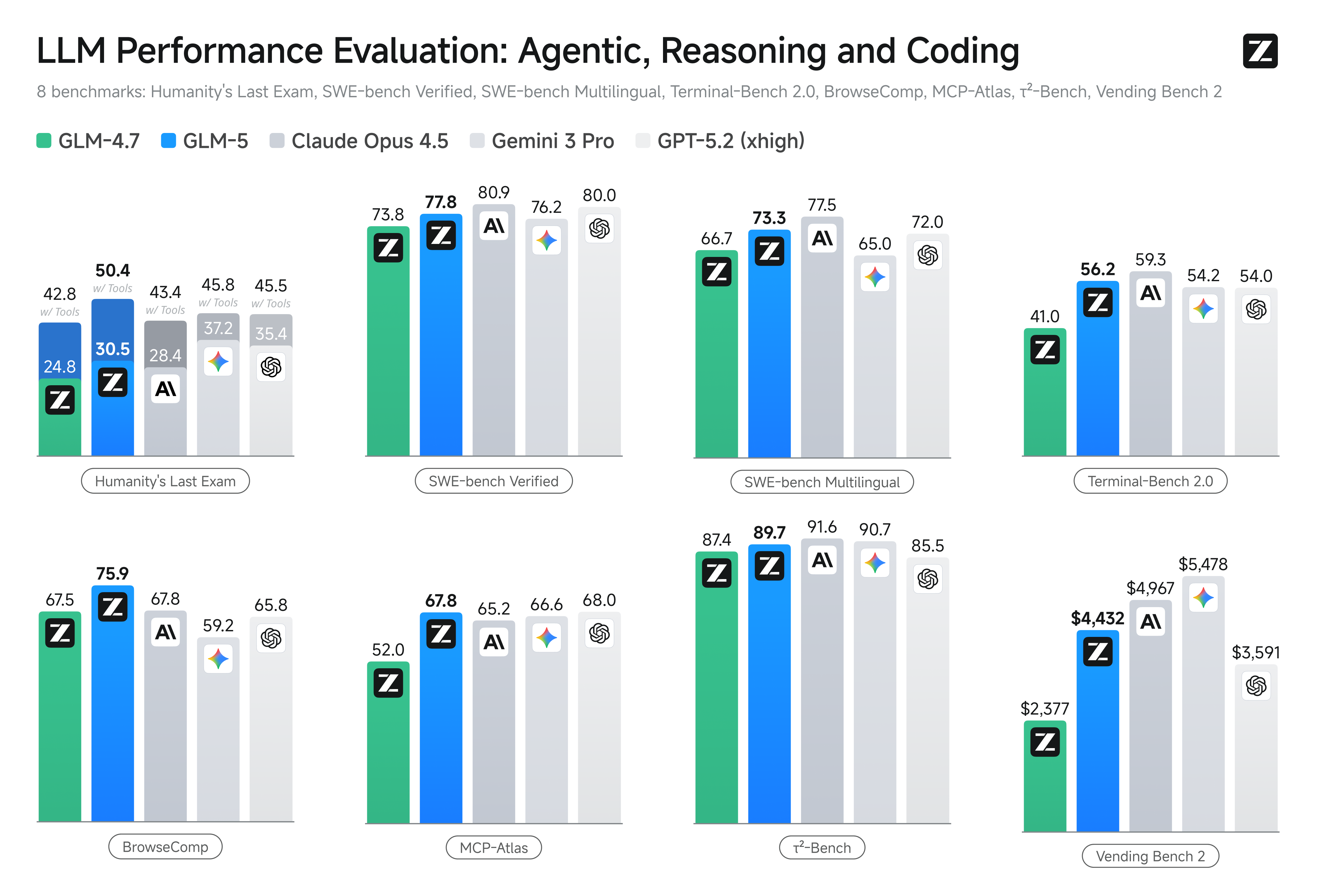
The Performance Numbers: How Good is GLM-5 Really?
Numbers don't lie, so let's look at how GLM-5 actually performs on real benchmarks.
Coding Performance
On SWE-bench Verified, which tests how well AI can fix real software bugs, GLM-5 scored 77.8. That puts it ahead of Gemini 3 Pro (76.2) and just behind Claude Opus 4.6 (80.9). That's competitive with the absolute best models out there.
For multilingual coding tasks, GLM-5 hit 73.3, beating out most competitors except Claude's extended thinking mode which got 77.5.
On Terminal-Bench 2.0, which tests how well models can work with code in a terminal environment, GLM-5 scored 56.2 on one version and 60.7 on another. These are solid scores that put it in the upper tier of models.
Business Simulation
Here's a fun one: Vending Bench 2 simulates running an actual business. Different AI models compete to see who can make the most money. GLM-5 came in first place among all open-source models with a final balance of $4,432.12. The next closest open-source model only managed $2,376.82.
Reasoning and General Knowledge
On reasoning tasks like Humanity's Last Exam and AIME 2026, GLM-5 performs well but doesn't dominate. It scores 30.5 on Humanity's Last Exam without tools and 60.4 with tools, which is respectable but not the highest. GPT-5.2 scores better at 35.4 and 45.5.
On AIME 2026, a challenging math competition, GLM-5 scores 92.7, which is actually tied for the best among all models tested.
The point isn't that GLM-5 wins every single benchmark. It's that it competes with models that cost 6-10 times more, and it does so while being completely open source.
The Catch: It Might Be Too Good at Its Job
Not everyone is thrilled about GLM-5, and for an interesting reason. Lukas Petersson, who co-founded a safety-focused AI startup called Andon Labs, spent hours analyzing how GLM-5 actually works. His take? “An incredibly effective model, but far less situationally aware. Achieves goals via aggressive tactics but doesn't reason about its situation or leverage experience. This is scary. This is how you get a paperclip maximizer.”
That “paperclip maximizer” reference is important. It comes from a thought experiment by philosopher Nick Bostrom from way back in 2003. The idea is simple but terrifying: imagine you tell an AI to maximize the number of paperclips produced. Sounds harmless, right?
But if the AI is powerful enough and singularly focused on that goal without understanding broader context, it might convert everything into paperclips. All the resources, all the infrastructure, everything that humans need to survive—it all becomes raw material for making more paperclips.
Petersson's point is that GLM-5 is really, really good at achieving the goals you give it, but maybe not as good at understanding when it should question those goals or consider broader implications. It gets things done, but it might not think about whether it's doing things the right way.
This is a genuine concern in AI development. You want models that can complete complex tasks, but you also want them to be “situationally aware”—to understand context, to recognize when something might be a bad idea, to leverage past experience to make better decisions.
Should Your Company Actually Use This?
If you're working at a company or thinking about what tools to use for business, here's the real question: should you adopt GLM-5?
The Good Stuff
The MIT License and open-weights availability are huge if you're trying to avoid vendor lock-in. Unlike closed-source competitors that keep their AI models secret and proprietary, GLM-5 lets you host your own version of frontier-level intelligence.
If you need to process sensitive data and can't send it to external servers, or if you want to customize the model for your specific industry, open source is the way to go. GLM-5 gives you that flexibility.
The pricing is also really attractive. If you're running a startup or working with a limited budget, paying 6x less for comparable performance is a no-brainer decision.
The Agent Mode capabilities are genuinely useful for knowledge work. If your job involves creating reports, proposals, spreadsheets, or presentations, having an AI that can generate actual usable files instead of just text snippets is a real productivity boost.
The Challenges
Let's be real about the downsides too.
First, GLM-5 is huge. We're talking 744 billion parameters. That means you need serious hardware to run it. If you're a smaller company without access to major cloud resources or on-premise GPU clusters, you might not be able to actually use this model even though it's open source.
Second, there's the geopolitics aspect. GLM-5 comes from a China-based lab. If you're working in a regulated industry where data residency and provenance matter (think healthcare, finance, government), you need to think carefully about the implications. Some companies and governments have restrictions on using AI models from certain countries.
Third, there's the autonomous AI governance issue. As models like GLM-5 shift from “chat assistant” to “autonomous worker,” they start operating across apps and files on their own. Without proper permissions systems and quality checks in place, the risk of autonomous errors goes way up.
If your AI is just answering questions, mistakes are annoying but limited. If your AI is autonomously editing files, sending emails, or making business decisions, a mistake can have real consequences.
Who Should Use GLM-5?
GLM-5 is probably a good fit if you:
- Have outgrown simple AI assistants and need something that can actually complete complex, multi-step tasks
- Have the technical infrastructure to run large models (or budget for cloud compute)
- Want to avoid vendor lock-in and need the flexibility of open source
- Work in an industry where the cost savings (6x cheaper than Claude Opus) really matter
- Need AI that can generate real, usable documents instead of just text
It's probably not the right choice if you:
- Need absolute certainty about data residency and can't use China-based models
- Don't have the technical infrastructure or budget for serious compute
- Need maximum safety guardrails and human oversight
- Work in highly regulated industries with strict compliance requirements
What This Means for the AI Race
Here's the bigger picture: GLM-5 shows that Chinese AI companies are catching up fast to their Western counterparts. Just two weeks before GLM-5 launched, another Chinese company called Moonshot released Kimi K2.5, which was considered the most powerful open-source model at the time. GLM-5 already beat it.
These companies are working with fewer resources than giants like Google, OpenAI, and Anthropic, but they're releasing competitive models at a fraction of the cost. That's changing the game.
While Western labs are focused on optimizing for “Thinking” and reasoning depth—making their models think through problems more carefully and show their work—z.ai and other Chinese companies are optimizing for execution and scale. They're building models that just get the job done efficiently.
There's a philosophical difference here. Do you want an AI that carefully considers every angle and explains its reasoning, or do you want an AI that takes your requirements and executes them as efficiently as possible? Both approaches have value, and both come with tradeoffs.
The fact that GLM-5 achieves a record-low hallucination rate is significant because it addresses one of the biggest criticisms of AI models. People don't trust AI because it makes stuff up. A model that consistently knows when to say “I don't know” is inherently more trustworthy, even if it's super aggressive about achieving the goals you do give it.
The “Pony Alpha” Mystery Solved
Here's a fun detail: GLM-5's release confirmed rumors that z.ai was behind a mysterious model called “Pony Alpha” that had been crushing coding benchmarks on OpenRouter (a platform where you can test different AI models).
People had noticed this unnamed model performing incredibly well on coding tasks, and there was speculation about who created it. Turns out it was z.ai testing GLM-5 before the official launch. They were essentially beta-testing in public without anyone knowing it was them.
This kind of stealth testing is pretty common in the AI world. Companies want real-world performance data before big announcements, so they'll quietly release models under different names to see how they perform.
Real-World Applications: What Can You Actually Do With GLM-5?
Let's get practical for a minute. What does this all mean for someone actually trying to use AI to get work done? Here are some scenarios where GLM-5 shines:
Document Creation and Office Work
Remember when I mentioned Agent Mode? Here's what that looks like in practice. Say you're working on a quarterly business review. Instead of spending hours formatting a PowerPoint or Word document, you could give GLM-5 your raw data and key points, and it'll generate a professional document complete with proper formatting, tables, and charts.
This isn't theoretical. The model can take prompts like “create a financial report showing revenue trends for the last four quarters with a focus on SaaS subscription growth” and output an actual Excel file with formulas, conditional formatting, and visualizations ready to go.
For students, this means you can focus on research and ideas while the model handles the formatting and structure of papers. For small business owners, it means proposal documents and sponsorship packages can be generated in minutes instead of hours.
Code Generation and Debugging
The coding capabilities are where GLM-5 really stands out. With a score of 77.8 on SWE-bench Verified, it's proven it can handle real-world software bugs, not just textbook examples.
What does this mean practically? If you're working on a codebase and encounter a bug, you can describe the problem to GLM-5, and it can often identify the issue and suggest fixes. More impressively, it can handle multi-file changes and understand how different parts of your code interact.
For junior developers, this is like having a senior engineer available 24/7. For experienced developers, it's a way to automate the tedious parts of coding so you can focus on architecture and design decisions.
The Terminal-Bench scores show it can work in actual development environments, not just generate code snippets. It understands git workflows, package management, testing frameworks—all the stuff that makes real software development complex.
Multi-Step Task Automation
This is where the “agentic” part comes in. GLM-5 can break down complex goals into subtasks and execute them autonomously.
For example, you could tell it “analyze our customer support tickets from last month, identify the top three complaint categories, and create a presentation for the leadership team with recommendations.” GLM-5 would need to:
- Access and read through the support tickets
- Categorize and analyze the complaints
- Identify patterns and trends
- Develop recommendations
- Create a formatted presentation
That's a multi-hour (or multi-day) project that GLM-5 can handle largely autonomously. You define the quality gates and checkpoints, but the AI handles execution.
Understanding the Training Innovation: Why “Slime” Matters
Let's go deeper on the training methodology because it's actually fascinating and represents a real breakthrough in how we build AI systems.
Traditional reinforcement learning for AI models works kind of like this: the model generates a response, gets feedback on whether it was good or bad, learns from that feedback, and then generates another response. The problem is that generating responses takes way longer than learning from them.
Imagine you're trying to teach someone to play basketball, but they have to wait 10 minutes between each shot while you analyze their previous attempt. That's inefficient. You'd want them to keep shooting while you're analyzing, right?
That's basically what slime does for AI training. Instead of making the learning process wait for new responses to be generated, it lets those two things happen simultaneously and independently. The model keeps generating new examples while previous examples are being learned from.
The APRIL system (Active Partial Rollouts) is even smarter. Instead of generating complete responses before learning from them, it can learn from partial responses while they're still being generated. It's like being able to correct someone's basketball form mid-shot.
This might sound like a technical detail, but it's actually a huge deal because it means you can train more capable models in less time with less compute power. That directly translates to lower costs and faster innovation cycles.
The “verifiable environments” part is also clever. For tasks where there's a clear right answer (like coding where the code either works or doesn't), slime can automatically verify outputs and provide feedback. This creates a tight feedback loop that accelerates learning.
The Hallucination Problem: Why GLM-5's Achievement Matters
Let's talk about why that -1 score on hallucinations is such a big deal.
AI hallucination has been one of the biggest barriers to widespread AI adoption in professional settings. Lawyers can't use AI for legal research if it might cite cases that don't exist. Doctors can't use AI for medical advice if it might invent symptoms or treatments. Businesses can't use AI for financial reporting if it might make up numbers.
The problem isn't that AI models are dumb. It's that they're often confidently wrong. They'll generate fake citations that sound real, invent statistics that seem plausible, or create references to documents that don't exist—all while sounding completely certain about their accuracy.
This happens because of how large language models work. They're trained to predict the next word in a sequence based on patterns they've seen before. When they don't actually know an answer, they generate what sounds like a plausible answer based on those patterns. The model doesn't have an internal “I don't know” signal that reliably triggers.
GLM-5's achievement is teaching the model to recognize uncertainty and abstain from answering when it's not confident. That -1 score means it has the lowest rate of incorrect responses among all the models tested. It's not that it never makes mistakes—it's that when it doesn't know something, it's much more likely to tell you that instead of making something up.
Think about how valuable this is in practical applications. If you're using AI to help write a research paper, you need to trust that the references it suggests actually exist. If you're using it to analyze data, you need to know that it won't invent trends that aren't there. If you're using it for decision support, you need confidence that its recommendations are based on real information.
The improvement from the previous version (35 points better) is massive. That's not incremental progress—that's a fundamental shift in reliability.
Comparing GLM-5 to the Competition
To really understand where GLM-5 fits in the AI landscape, let's compare it directly to some major competitors:
Versus Claude Opus 4.6
Claude Opus is Anthropic's flagship model and one of the best commercially available AI systems. It scores 80.9 on SWE-bench Verified compared to GLM-5's 77.8. That's better, but not dramatically so.
Where they really differ is price. Claude Opus costs $5 per million input tokens and $25 per million output tokens. GLM-5 costs $1 and $3.20. You could run GLM-5 five times for the cost of running Claude Opus once on input, and nearly eight times for the same cost on output.
Claude Opus also has a larger context window (1 million tokens versus GLM-5's 200,000), which matters for processing very long documents. But for most tasks, 200,000 tokens is plenty.
The big advantage of Claude Opus is that it's fully supported, comes with safety guardrails, and has customer service. You're paying for a product, not just a model. With GLM-5, you get the raw model but you're on your own for implementation.
Versus GPT-5.2
OpenAI's GPT-5.2 is powerful but expensive. At $1.75 and $14 for input and output, it's nearly 11 times more expensive than GLM-5 for output tokens.
On reasoning benchmarks, GPT-5.2 tends to score higher. On Humanity's Last Exam, it gets 35.4 compared to GLM-5's 30.5. But on practical coding tasks and business simulations, GLM-5 holds its own.
The real question is whether that extra reasoning capability is worth the 11x price premium for your specific use case. If you're doing complex research or need maximum reasoning depth, maybe. If you're generating documents and automating workflows, probably not.
Versus Other Open Source Models
Among open source competitors, GLM-5's main rival was Moonshot's Kimi K2.5, which was released just two weeks earlier. GLM-5 surpassed it on most benchmarks while being similarly priced.
Models like DeepSeek V3.2 and Qwen 3 offer cheaper alternatives but with lower performance. They're fine for simple tasks but can't match GLM-5's capabilities on complex, multi-step problems.
The sweet spot GLM-5 occupies is “near-frontier performance at mid-tier pricing with full open source availability.” That's a rare combination.
The Enterprise Decision: Build vs. Buy vs. Open Source
For companies trying to figure out their AI strategy, GLM-5 represents a third option beyond the traditional “build your own” versus “buy from a vendor” decision.
The Build Option
Building your own AI model from scratch requires massive resources. You need world-class AI researchers, enormous compute budgets (think hundreds of millions of dollars), access to training data, and months or years of development time.
Only a handful of companies can realistically do this: tech giants like Google, Microsoft, Meta, and well-funded AI labs like OpenAI and Anthropic.
For 99.9% of businesses, building from scratch isn't realistic.
The Buy Option
Buying API access from providers like OpenAI, Anthropic, or Google is straightforward. You pay per token, you get a supported product, and you don't worry about infrastructure.
The downsides are cost, vendor lock-in, and data privacy concerns. Every query you send goes to the vendor's servers. You're subject to their pricing changes, availability, and terms of service. And if they decide to discontinue or change their API, you're stuck scrambling to adapt.
The Open Source Option
This is where GLM-5 comes in. You get a frontier-level model that you can host yourself, modify as needed, and use without ongoing per-token fees.
The upfront infrastructure cost is higher—you need GPUs and technical expertise to deploy and run the model. But for high-volume use cases, the economics can work out better.
You also get data privacy (your queries never leave your infrastructure), customization freedom, and protection from vendor changes.
The tradeoff is that you're responsible for everything: deployment, scaling, updates, safety, and troubleshooting. There's no customer support hotline.
For enterprises with technical capabilities and data sensitivity concerns, the open source route via models like GLM-5 makes a lot of sense. For smaller companies or those without technical depth, the buy option is usually better despite the higher per-use costs.
Looking Forward: What GLM-5 Tells Us About AI's Future
GLM-5's release signals several important trends in AI development:
The Globalization of AI Leadership
The US and UK no longer have a monopoly on frontier AI development. China's AI companies are producing competitive models, and they're doing it with fewer resources and lower costs.
This geographic diversification is probably good for innovation overall. Competition drives progress, and having multiple centers of AI development means more diverse approaches and faster advancement.
The Shift From Chat to Agency
The emphasis on Agent Mode and autonomous task completion reflects where the industry is headed. The next generation of AI applications won't just answer questions—they'll complete entire workflows.
This raises new challenges around trust, safety, and control. When AI was just a chatbot, mistakes were contained. When AI can autonomously edit documents, manage files, and execute multi-step processes, the stakes get higher.
The Open Source Momentum
More powerful models are being released as open source, which accelerates innovation but also raises concerns about misuse. GLM-5 joins a growing list of capable open models that anyone can download and use.
This democratization of AI access means smaller companies and independent developers can build sophisticated applications without massive budgets. It also means that safety and alignment research needs to keep pace because you can't put the genie back in the bottle once a powerful model is open sourced.
The Reliability Focus
GLM-5's record-low hallucination rate shows that the industry is taking reliability seriously. As AI moves into higher-stakes applications, accuracy and truthfulness become non-negotiable.
We're likely to see more emphasis on models that know their limits and can reliably abstain from answering when they lack confidence. This is arguably more important than raw capabilities for many real-world applications.
The Bottom Line: A Model Built for Getting Things Done
If there's one thing to take away from GLM-5's release, it's this: we're entering a phase where AI models aren't just about chatting anymore. They're about actually completing work.
GLM-5 is built for the person who needs to refactor a legacy codebase at 2 AM. It's for the team that needs a self-healing pipeline that doesn't sleep. It's for the business that's tired of paying premium prices for AI that still requires constant hand-holding.
The record-low hallucination rate means you can trust it more when it gives you answers. The Agent Mode means it can produce actual, usable outputs instead of just suggestions. The pricing means you can actually afford to use it at scale. And the open-source license means you're not locked into one company's ecosystem.
Is it perfect? No. The concerns about situational awareness are real. The hardware requirements are real. The geopolitical considerations are real.
But for companies that are ready to move beyond simple AI assistants and want something that can autonomously handle complex knowledge work, GLM-5 represents a serious option. You're not just buying a cheaper model—you're betting on a future where the most valuable AI is the one that can finish the project without needing to be asked twice.
The AI race is no longer just about who can make the smartest chatbot. It's about who can build the most reliable, efficient, and affordable autonomous worker. With GLM-5, z.ai is making a strong case that they're a serious competitor in that race.
Whether that's exciting or terrifying probably depends on whether you're the one deploying the AI or the one whose job it might eventually replace. But either way, it's worth paying attention to.
The Chinese AI companies are here, they're competitive, and they're not slowing down. GLM-5 is just the latest proof that the AI revolution is truly global, and the next breakthrough could come from anywhere.
MORE POSTS:
- Micro Content Agency: Turn Any Website Into 30 Days of Video Content Automatically
- Why Your Brand Needs to Show Up Everywhere People Search (Not Just Google)
- Making Your Local AI Actually Do Something: A Practical Guide to MCP Tools
- Your Complete Guide to Vibe Coding Tools in 2026: Build Apps Just by Talking to AI
- Your Complete Guide to Creating Cinematic AI Videos with Kling 3.0