How MIT’s Attention Matching Shrinks AI Memory by 50x Without Breaking Anything

How MIT's Attention Matching Shrinks AI Memory by 50x Without Breaking Anything
Imagine you are chatting with an AI assistant, asking it to read through a 200-page legal contract and answer detailed questions about the fine print. Halfway through the conversation, the AI starts forgetting things it read earlier. It gives you vague answers. It misses details it definitely processed before. The conversation falls apart.
That is not a bug in the model's intelligence. It is a memory problem. A very specific, very technical, and very fixable memory problem called the KV cache bottleneck.
MIT researchers just published a technique that tackles this problem head-on. Their method, called Attention Matching, can compress an AI's working memory by up to 50 times its original size without meaningfully reducing what the model actually knows or how accurately it responds. And it does this in seconds, not hours.
That last part matters more than you might think.
What Even Is a KV Cache?
Before getting into why this is a big deal, it helps to understand what a KV cache actually is.
Large language models do not think the way humans do. They generate responses one word (technically one “token”) at a time. Every single time the model predicts the next word, it needs to look back at everything said so far in the conversation to make sure the new word makes sense in context.
Doing that from scratch every single time would be incredibly slow. So the model cheats a little. It stores a compressed mathematical record of everything it has already processed. This stored record is the KV cache, which stands for Key-Value cache. The “keys” and “values” here are specific mathematical structures that represent past context in a format the model's attention mechanism can quickly scan.
Think of it like taking notes while reading a long book. Instead of re-reading the entire book every time you want to answer a question, you flip to your notes. The KV cache is those notes.
The problem is those notes take up a lot of space.
The Memory Wall AI Is Hitting Right Now
Every new token added to a conversation adds more data to the KV cache. The longer the conversation, the bigger the cache. For short chats, this is no problem. For enterprise use cases, it becomes a genuine crisis.
Adam Zweiger, one of the co-authors of the Attention Matching paper, put it plainly when speaking with VentureBeat: “In practice, KV cache memory is the biggest bottleneck to serving models at ultra-long context. It caps concurrency, forces smaller batches, and/or requires more aggressive offloading.”
What does that mean in real terms?
- An AI processing a massive legal contract might use several gigabytes of memory just for one user's session.
- A customer service agent maintaining long conversation histories across multiple interactions burns through hardware fast.
- An autonomous coding assistant that needs to keep thousands of lines of code in context hits physical memory limits and slows down or crashes.
This is not a hypothetical future problem. It is happening right now in production environments. Companies running AI at scale are burning through GPU memory and paying for it.
The Workarounds That Do Not Actually Work
The AI industry has been aware of this problem and has tried various fixes. None of them are great.
Dropping Old Context
The simplest approach is to just delete old information when memory fills up. The model forgets the beginning of the conversation to make room for what comes next. This is fast, cheap, and terrible for accuracy. Important details from earlier in the context get wiped permanently. For anything requiring full document understanding, this approach collapses quickly.
Summarizing the Context
A slightly smarter approach is summarization. When memory gets full, the model pauses and writes a short text summary of the older content. That summary replaces the original memory, freeing up space.
This sounds reasonable. In practice, it falls apart badly for dense information. Summarization is what researchers call “lossy,” meaning it throws away details to save space. For general conversation, you might not notice. But for something like detailed medical records or complex legal clauses, the model starts performing as if it never read the document at all.
The MIT researchers actually tested this. When they ran a standard summarization approach on dense medical patient records (a 60,000-token dataset called LongHealth), the model's accuracy dropped so severely it matched what the model would have scored if it had been given no context at all. The summary contained so little of the original detail that it was essentially useless.
Token Dropping and Merging
Some techniques try to be smarter about which parts of the KV cache to keep. They identify tokens the model seems to pay less attention to and remove them, or merge similar tokens together. These methods work reasonably well for mild compression, maybe compressing memory by a factor of two or three. Pushed harder, they degrade fast.
Cartridges: The Promising But Slow Option
A more recent approach called Cartridges showed it was technically possible to do high-quality, high-ratio compression. The idea was to use gradient-based optimization to “train” a compact version of the KV cache that preserved the original's behavior.
The results were genuinely impressive in terms of quality. The problem was time. Compressing a single context using Cartridges could take several hours of heavy GPU computation. For a real-time application where a user expects an answer in seconds, that is completely unworkable.
Attention Matching: The Approach That Changes Things
This is where MIT's new technique comes in. Attention Matching achieves high compression ratios at high quality, but it does so in seconds rather than hours. That gap is enormous.
The key insight behind Attention Matching is about what properties of the KV cache actually need to be preserved for the model to behave correctly.
The researchers identified two properties that matter most:
1. Attention Output: This is the actual information the model extracts when it queries its memory. It is what the model “reads” from its notes when forming a response.
2. Attention Mass: This is essentially how much mathematical weight a given piece of information carries relative to everything else. It influences how strongly any particular memory influences the model's next prediction.
If a compressed version of the KV cache can match both of these properties accurately, the model will behave almost identically to how it would with the full, uncompressed cache, even when new and unpredictable user questions are introduced later.
As Zweiger explained: “Attention Matching is, in some ways, the ‘correct' objective for doing latent context compaction in that it directly targets preserving the behavior of each attention head after compaction.”
That is the theoretical foundation. Now here is how it actually works in practice.
How the Compression Process Actually Runs
Attention Matching with Qwen-3 (source: arXiv)
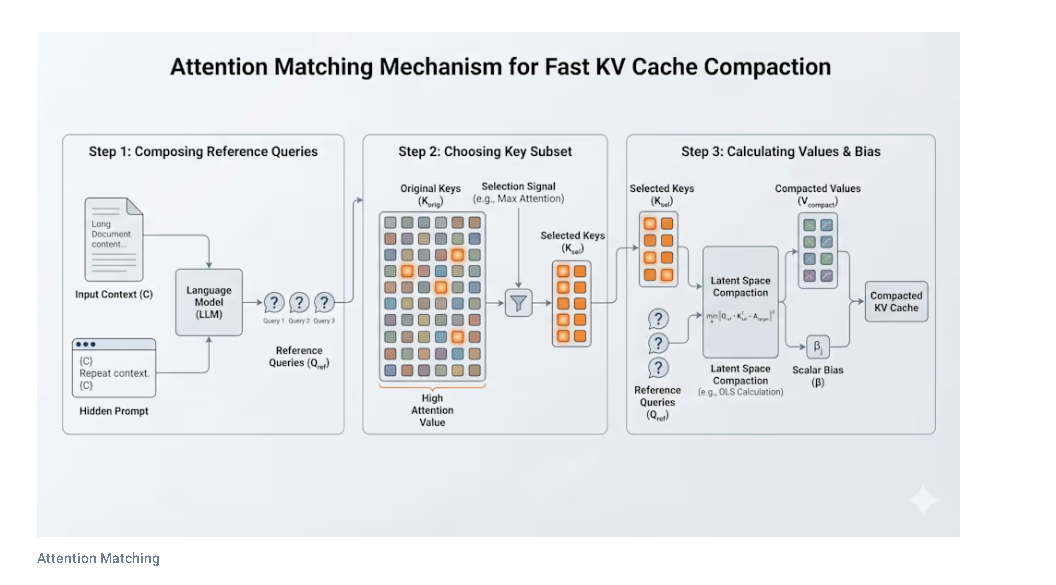
Step One: Generate Reference Queries
Before compressing anything, the system first creates a small set of “reference queries.” These are questions or tasks designed to mimic the kinds of internal searches the model is likely to run when it thinks about this particular document.
The idea is: if the compressed memory can correctly handle these reference queries, it will almost certainly handle whatever the user actually asks later.
The researchers came up with a few creative ways to generate these reference queries:
- A “repeat-prefill” technique where a hidden prompt tells the model to recall the previous context.
- A “self-study” approach where the model is asked to quickly perform synthetic tasks on the document, like pulling out all key facts or formatting dates into a JSON structure.
These tasks force the model to engage with the document in meaningful ways, creating queries that genuinely probe what matters in the content.
Step Two: Select Which Keys to Keep
With reference queries in hand, the system selects a set of keys to preserve from the original KV cache. The selection is guided by signals like which keys received the highest attention values during the reference query process. High attention means the model found that information important, so it gets kept.
Step Three: Recalculate Values Using Algebra
Here is where Attention Matching separates itself from gradient-based methods in a very practical way.
Instead of using slow iterative training to calculate the optimal values for the preserved keys, the system uses simple algebraic techniques. Things like ordinary least squares and nonnegative least squares. These are fast mathematical operations that can be solved directly without any back-and-forth training loop.
The system also calculates a scalar bias term for each retained key. This bias acts as a kind of compensation mechanism, allowing each kept key to mathematically represent the information of all the keys that were removed. The result is a small cache that punches far above its size.
Step Four: Chunked Compaction for Long Documents
For very long documents, the researchers apply what they call chunked compaction. The document is broken into consecutive segments, each compressed independently, and then the results are joined back together. This approach improves performance on the kinds of extremely long contexts that are common in enterprise settings.
What the Tests Actually Showed
The researchers ran Attention Matching against real-world benchmarks using popular open-source models including Llama 3.1 and Qwen-3.
They tested on two datasets:
- QuALITY: A reading comprehension benchmark using documents between 5,000 and 8,000 words. Standard length for enterprise reports.
- LongHealth: A 60,000-token dataset of complex medical records for multiple patients. This is the kind of dense, information-packed context where most compression methods fall apart.
The results on LongHealth were particularly telling. Standard summarization essentially zeroed out in terms of usefulness, as mentioned earlier. Attention Matching drastically outperformed it while maintaining genuine accuracy.
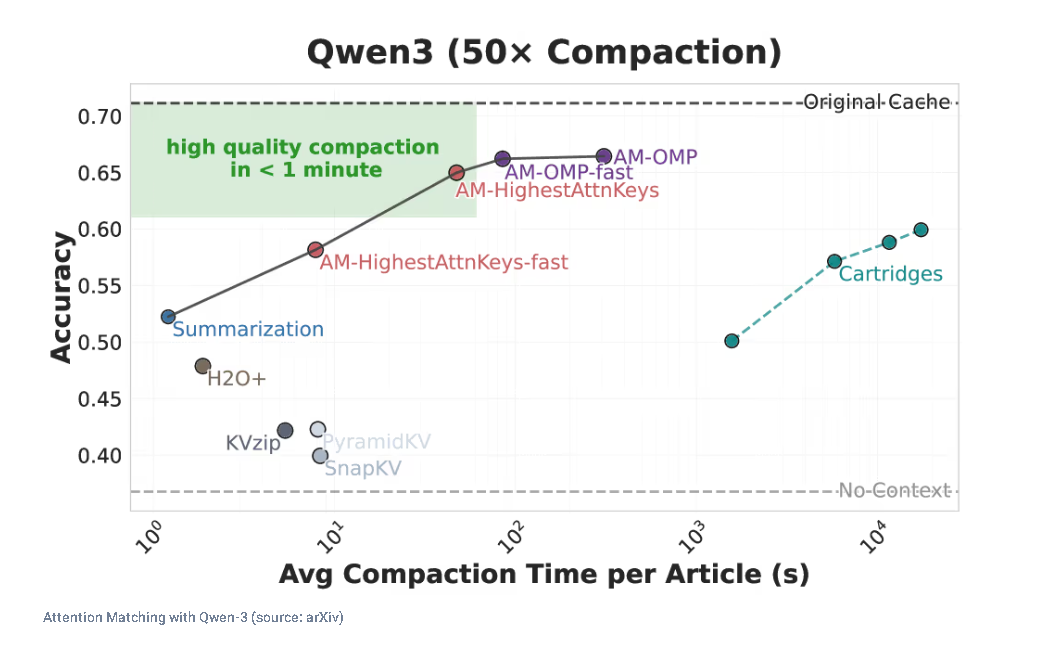
At a 50x compression ratio, Attention Matching consistently outperformed all other fast methods in terms of balancing speed and quality. The compression that used to take hours on expensive hardware now takes seconds.
The researchers also tested a stacked approach: running Attention Matching on top of a standard text summary. This combined method achieved 200x compression while successfully matching the accuracy of summarization alone, but with a dramatically smaller memory footprint. For cases where precision is not critical but memory is extremely tight, this is a viable path.
Live Memory Management: The Online Compaction Experiment
One of the most interesting experiments in the paper was something called online compaction, which the researchers themselves describe as a proof of concept rather than a production-ready feature.
The test worked like this: the model was given a hard memory limit. It had to solve a complex math problem from the AIME benchmark, a set of competition-level math questions. Whenever its working memory hit the ceiling, the system paused and immediately compressed the KV cache by 50 percent using Attention Matching, then let the model continue.
The model hit this memory wall six times in a row during some problems. Each time, its memory was halved. Yet it kept solving the problems correctly. Its final scores matched a version of the model that had been given unlimited memory with no compression at all.
This is a striking demonstration of how real-time, on-the-fly compression could work in future AI systems. Instead of crashing or degrading when memory runs out, the model compresses what it has and keeps going.
The Honest Tradeoffs You Should Know About
Attention Matching is not perfect for every situation. The researchers are clear about this.
At 50x compression, it is the best available option for balancing speed and quality. But if you push compression ratios to 100x or beyond on highly complex, information-dense data, the slower gradient-based Cartridges method actually starts to outperform it. There is a ceiling.
Zweiger also notes that for highly information-dense tasks, you generally need a milder compression ratio to maintain strong accuracy. In other words, if your document is packed with critical details, you cannot compress quite as aggressively and expect the same results as with a more general document.
Additionally, this is not something you can just plug into any existing AI product overnight.
“I think latent compaction is best considered a model-layer technique,” Zweiger said. “While it can be applied on top of any existing model, it requires access to model weights.”
That means if your organization relies entirely on closed APIs, like accessing models through a vendor's API without any access to the actual model files, you cannot implement this yourself. You need open-weight models where the internal parameters are accessible.
Integrating Attention Matching into existing, heavily optimized commercial inference systems also requires real engineering effort. Modern AI infrastructure uses techniques like prefix caching and variable-length memory packing that are finely tuned for performance. Adding a new compression layer on top of these systems is not trivial.
Where This Is Most Immediately Useful
Despite the limitations, there are practical applications that can benefit from this technique right now.
Zweiger highlighted one specific use case that fits particularly well: “We believe compaction after ingestion is a promising use case, where large tool call outputs or long documents are compacted right after being processed.”
Think about what that means practically:
- An AI agent that reads through a 100-page legal filing can compress that document's representation immediately after reading it, freeing up memory for the rest of the conversation.
- A coding assistant that ingests a large codebase can compact its representation of the code and then work with it in a smaller memory footprint.
- A customer support system that reads through a user's full account history can compress that history into a compact representation before starting the conversation.
The compression happens once, immediately after ingestion, and then the smaller footprint is used for everything that follows. This fits naturally into existing workflows without requiring real-time on-the-fly compression during every response.
The Bigger Picture: Who Controls This Technology
There is a broader shift happening in the AI industry that this research points to. For a while, memory compression was something that individual companies and developers had to implement themselves, often with hacky workarounds and inconsistent results.
What the MIT researchers are arguing, and what Zweiger makes explicit, is that this is increasingly becoming something that model providers themselves will build into their infrastructure.
“We are seeing compaction shift from something enterprises implement themselves into something model providers ship,” Zweiger said. “This is even more true for latent compaction, where access to model weights is needed.”
This makes sense. If you need access to the model's weights to do high-quality compression, and most enterprise users do not have that access, then the only parties who can realistically implement this well are the organizations that build and host the models themselves.
You can read the full technical paper over at arXiv if you want to go deeper into the math.
What This Means for AI Going Forward
The code for Attention Matching has been released publicly. The research team is not keeping this proprietary. That matters because it means other researchers and developers can build on this work, test it against different models, and push the compression ratios and accuracy benchmarks further.
For anyone building AI applications that deal with long documents, this research is directly relevant. The memory bottleneck is real and it costs money, time, and accuracy. A technique that achieves 50x compression in seconds without meaningful accuracy loss changes the math on what is practically possible.
Think about what that unlocks for fields like medicine, law, education, and software development. An AI system that can hold the equivalent of a novel's worth of technical documentation in memory and respond accurately to detailed questions about any part of it is genuinely useful in ways that current systems often are not.
For a 22-year-old thinking about where AI is actually headed, this is a good place to look. The headline-grabbing stuff is usually about what models can say or generate. The quieter, more important work is often about what they can actually remember, and for how long, and how efficiently. The memory problem is the unglamorous infrastructure problem that determines whether AI is actually practical at scale.
Attention Matching is a real step toward making that infrastructure work.
The researchers are careful not to overstate what they have built. This is not a simple product update. It is not something most people will interact with directly. But it is the kind of foundational work that, six months or a year from now, gets quietly folded into the AI tools millions of people use every day, making them faster, cheaper to run, and significantly more capable of handling the kinds of complex, long-form tasks that actually matter in the real world.
That is worth paying attention to.
Why Speed Is the Feature Nobody Talks About Enough
When people evaluate AI research, they tend to focus on accuracy benchmarks. Did the model get the right answer? By what percentage did it beat the previous approach? Those numbers matter, but they tell an incomplete story.
Speed is often the feature that determines whether something is actually usable. A compression technique that achieves perfect accuracy but takes four hours per document is, for almost all real applications, worthless. You cannot build a live application around it. You cannot charge users for it. You cannot scale it.
The reason Cartridges never made it into production environments despite strong accuracy numbers was exactly this. Hours of GPU time per context is not a pipeline. It is a science experiment.
Attention Matching closes that gap. Seconds versus hours is not an incremental improvement. It is a category shift. It means the technique can actually sit inside a running application, compress contexts as users interact with the system, and do so without anyone noticing a delay.
That is why this specific paper matters beyond its technical contributions. It is not just that the math works. It is that the math works fast enough to be used in the real world. That combination is genuinely rare in AI research.
Thinking About the Future of AI Memory
If you step back from the technical details, there is a broader pattern worth seeing here.
AI models have gotten dramatically smarter over the past few years. Their raw capabilities, what they can reason through, what they can generate, what they can understand, have improved at a pace that surprised even the people building them. But the underlying infrastructure that allows those capabilities to be used in practice has not always kept up.
Memory management is one of the clearest examples of that gap. You can have the most capable model in the world, but if it forgets the first half of a conversation by the time it gets to the second half, its capability becomes largely theoretical.
Attention Matching is one piece of a larger puzzle. Other pieces include better hardware designed with AI memory in mind, smarter inference engines that manage memory more efficiently at the system level, and architectural changes to models themselves that reduce how much memory they need in the first place.
Progress on any one of these fronts makes AI more practically useful. Progress on multiple fronts at once could make it dramatically more useful for the kinds of long, complex, multi-step tasks where AI currently struggles most.
For now, the MIT team has released their code. Other researchers can test it, break it, improve it, and apply it to models and use cases the original team never considered. That openness is how good ideas in research actually spread and become useful technology.
More Posts:
- How Claude Code Was Built: The Engineer Behind the AI Coding Tool Changing How We Write Software
- How To Launch Instagram Agents That Build Self-Learning & Scaling ‘Living’ Video Channels & Businesses For You Using GramGenies
- Create & Own Realistic Virtual Influencers/Digital Twins That Go Viral & Build Your Profitable Brand In Any Niche Using Imimic AI
- How Runlayer Is Turning the AI Agent Security Crisis Into a Solved Problem for Big Companies
- Building a Stock Market AI Copilot From Scratch: LangChain, Real Data APIs, and a Clickable App
Source: MIT research via arXiv